
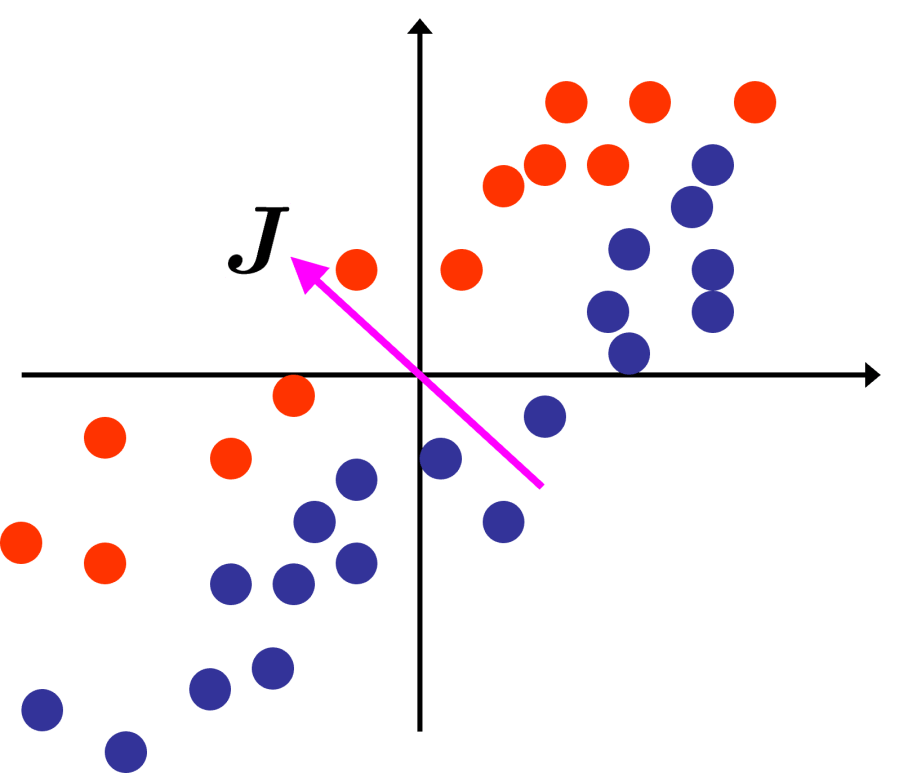
TL;DR: Both Principal Components Analysis (PCA) and Minor Components Analysis (MCA) can be used for dimensionality reduction, identifying low-dimensional subspaces of interest as those which have the greatest variation in the original data (PCA), or those which have the least variation in the origina data MCA). As real data will contain both directions of unusually high variance and directions of unusually low variance, using just PCA or just MCA will lead to biased estimates of the low-dimensional subspace. The 2003 NeurIPs paper from Welling et al unifies PCA and MCA into a single probabilistic model XCA (Extreme Components Analysis). This post explains the XCA paper of Welling et al and demonstrates the XCA algorithm using simulated data. Code for the demonstration is available from https://github.com/dchoyle/xca_post
A deadline
This post arose because of a deadline I have to meet. I don’t know when the deadline is, I just know there is a deadline. Okay, it is a self-imposed deadline, but it will start to become embarrassing if I don’t hit it.
I was chatting with a connection, Will Faithfull, at a PyData Manchester Leaders meeting almost a year ago. I mentioned that one of my areas of expertise was Principal Components Analysis (PCA), or more specifically, the use of Random Matrix Theory to study the behaviour of PCA when applied to high-dimensional data.
A recap of PCA
In PCA we are trying to approximate a d-dimensional dataset by a reduced number of dimensions 




Once we have the (symmetric) matrix 
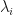
The optimal 
That is a heuristic derivation/justification of PCA (minus the detailed maths) that goes back to Harold Hotelling in 19332. There is a probabilistic model-based derivation due to Tipping and Bishop (1999), which we will return to later.
MCA
Will responded that as part of his PhD, he’d worked on a problem where he was more interested in the directions in the dataset along which the variation is least. The problem Will was working on was “unsupervised change detection in multivariate streaming data”. The solution Will developed was a modular one, chaining together several univariate change detection methods each of which monitored a single feature of the input space. This was combined with a MCA feature extraction and selection pre-processing step. The solution was tested against a problem of unsupervised endogenous eye blink detection.
The idea behind Will’s use of MCA was that for the streaming data he was interested in it was likely that the inter-class variances of various features were likely to be much smaller than intra-class variances, and so any principal components were likely to be dominated by what the classes had in common rather than what had changed, so the directions of greatest variance weren’t very useful for his change detection algorithm.
I’ve put a link here to Will’s PhD in case you are interested in the details of the problem and solution – yes, Will I have read your PhD.
Directions of least variance in a dataset can be found from the same eigen-decomposition of the sample covariance matrix and by selecting the components with the smallest non-zero eigenvalues. Unsurprisingly, focusing on directions of least variance in a dataset is called Minor Components Analysis (MCA)3,4. Where we have the least variation in the data the data is effectively constrained so, MCA is good for identifying/modelling invariants or constraints within a dataset.
At this point in the conversation, I recalled the last time I’d thought about MCA. That was when an academic colleague and I had a paper accepted at the NeurIPs conference in 2003. Our paper was on kernel PCA applied to high-dimensional data, in particular the eigenvalue distributions that result. As I was moving job and house at the time I was unable to go the conference, so my co-author, Magnus Rattray (now Director of the Institute for Data Science and Artificial Intelligence at the University of Manchester), went instead. On returning, Magnus told me of an interesting conversation he’d had at the conference with Max Welling about our paper. Max also had a paper at the conference, on XCA – Extreme Components Analysis. Max and his collaborators had managed to unify PCA and MCA into a single framework.
I mentioned the XCA paper to Will at the PyData Manchester Leaders meeting and said I’d write something up explaining XCA. It would also give me an excuse to revisit something that I hadn’t looked at since 2003. That conversation with Will was nearly a year ago. Another PyData Manchester Leaders meeting came and went and another will be coming around sometime soon. To avoid having to give a lame apology I thought it was about time I wrote this post.
XCA
Welling et al rightly point out that if we are modelling a dataset as lying in some reduced dimensionality subspace then we consider the data as being a combination of variation and constraint. We have variation of the data within a subspace and a constraint that the data does not fall outside the subspace. So we can model the same dataset focusing either on the variation (PCA) or on the constraints (MCA).
Note that in my blog post I have used a different, more commonly used notation. for the number of features and the number of components, than that used in the Welling et al paper. The mapping between the two notations is given below,
- Number of features: My notation =
, Welling et al notation =
- Number of components: My notation =
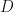
Probabilistic PCA and MCA
PCA and MCA both have probabilistic formulations, PPCA and PMCA5 respectively. Welling et al state that, “probabilistic PCA can be interpreted as a low variance data cloud which has been stretched in certain directions. Probabilistic MCA on the other hand can be thought of as a large variance data cloud which has been pushed inward in certain directions.” In both probabilistic models a 

The matrix 

In MCA the covariance matrix is modelled as,

The matrix 


Since in real data we probably have both exceptional directions whose variance is greater than the bulk and exceptional directions whose variance is less than the bulk, both PCA and MCA would lead to biased estimates for these datasets. The problem is that if we use PCA we lump the low variation eigenvalues (minor components) in with our estimate of the isotropic noise, thereby underestimating the true noise variance and consequently biasing our estimate of the large variation PC subspace. Likewise, if we use MCA, we lump all the large variation eigenvalues (principal components) into our estimate of the noise and overestimate the true noise variance, thereby biasing our estimate of the low variation MC subspace.
Probabilistic XCA
In XCA we don’t have that problem. In XCA we include both large variation and small variation directions in our reduced dimensionality subspace. In fact we just have a set of orthogonal directions 



As with probabilistic PCA, we then add on top an isotropic noise component to the overall covariance matrix. However, the clever trick used by Welling et al was that they realized that adding noise always increases variances, and so adding noise to all features will make the minor components undetectable as the minor components have, by definition, variances below that of the bulk noise. To circumvent this, Welling et al only added noise to the subspace orthogonal to the subspace spanned by the vectors 


and the XCA model is,

We can also start from the MCA side, by defining a projection operator 


The two probabilistic forms of XCA are equivalent and so one finds that the matrices

If we also look at the two ways in which Welling et al derived a probabilistic model for XCA, we can see that they are very similar to the formulations of PPCA and PMCA respectively, just with the replacement of 


Note that we are now defining the minor components subspace as directions of unusually low variance, so we only need a few dimensions, i.e. 

Maximum Likelihood solution for XCA
The model likelihood is easily written down and the maximum likelihood solution identified. As one might anticipate the maximum-likelihood estimates for the vectors 
Let’s say we want to retain 

![\log L_{ML} = - \frac{Nd}{2}\log \left ( 2\pi e\right )\;-\;\frac{N}{2}\sum_{i\in {\cal{C}}}\lambda_{i}\;-\;\frac{N(d-k)}{2}\log \left ( \frac{1}{d-k}\left [ {\rm tr}\hat{\underline{\underline{C}}} - \sum_{i\in {\cal{C}}} \lambda_{i}\right ]\right )](https://s0.wp.com/latex.php?latex=%5Clog+L_%7BML%7D+%3D+-+%5Cfrac%7BNd%7D%7B2%7D%5Clog+%5Cleft+%28+2%5Cpi+e%5Cright+%29%5C%3B-%5C%3B%5Cfrac%7BN%7D%7B2%7D%5Csum_%7Bi%5Cin+%7B%5Ccal%7BC%7D%7D%7D%5Clambda_%7Bi%7D%5C%3B-%5C%3B%5Cfrac%7BN%28d-k%29%7D%7B2%7D%5Clog+%5Cleft+%28+%5Cfrac%7B1%7D%7Bd-k%7D%5Cleft+%5B+%7B%5Crm+tr%7D%5Chat%7B%5Cunderline%7B%5Cunderline%7BC%7D%7D%7D+-+%5Csum_%7Bi%5Cin+%7B%5Ccal%7BC%7D%7D%7D+%5Clambda_%7Bi%7D%5Cright+%5D%5Cright+%29&bg=ffffff&fg=111111&s=0&c=20201002)
All we need to do is evaluate the above equation for all possible subsets 
For example, in our hypothetical example we have said we want 



Some of the terms in 



PCA and MCA as special cases
Potentially, we could find that
- A log-convex sample covariance eigen-spectrum will give PCA
- A log-concave sample covariance eigen-spectrum will give MCA
- A sample covariance eigen-spectrum that is neither log-convex nor log-concave will yield both principal components and minor components
In layman’s terms, if the plot of the (sorted) eigenvalues on a log scale only bends upwards (has positive second derivative) then XCA will give just principal components, whilst if the plot of the (sorted) eigenvalues on a log scale only bends downwards (has negative second derivative) then we’ll get just minor components. If the plot of the log-eigenvalues has places where the second derivative is positive and places where it is negative, then XCA will yield a mixture of principal and minor components.
Experimental demonstration
To illustrate the XCA theory I produced a Jupyter notebook that generates simulated data containing a known number of principal components and a known number of minor components. The simulated data is drawn from a zero-mean multivariate Gaussian distribution with population covariance matrix 


The first 



We would expect the eigenvalues of the sample covariance matrix to follow a similar pattern to the eigenvalues of the population covariance matrix that we used to generate the data, i.e. we expect a small group of noticeably low-valued eigenvalues, a small group of noticeably high-valued eigenvalues, and the bulk (majority) of the eigenvalues to form a continuous spectrum of values.
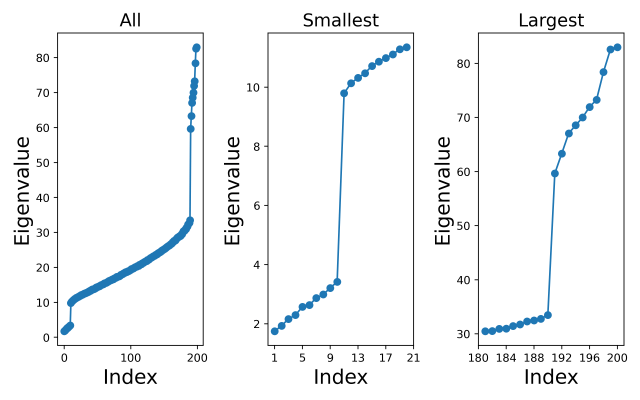
I generated a dataset consisting of 


The left-hand plot below shows all the eigenvalues (sorted from lowest to highest), and I have also zoomed in on just the smallest values (middle plot) and just the largest values (right-hand plot). We can clearly see that the sample covariance eigenvalues follow the pattern we expected.
All the code (with explanations) for my calculations are in a Jupyter notebook and freely available from the github repository https://github.com/dchoyle/xca_post
From the left-hand plot we can see that there are places where the sample covariance eigenspectrum bends upwards and places where it bends downwards, indicating that we would expect the XCA algorithm to retain both principal and minor components. In fact, we can clearly see from the middle and right-hand plots the distinct group of minor component eigenvalues and the distinct group of principal component eigenvalues, and how these correspond to the distinct groups of extreme components in the population covariance eigenvalues. However, it would be interesting to see how the XCA algorithm performs in selecting a value for the number of principal components.
For the eigenvalues above I have calculated the minimum value of 


Final comments
That is the post done. I can look Will in the eye when we meet for a beer at the next PyData Manchester Leaders meeting. The post ended up being longer (and more fun) than I expected, and you may have got the impression from my post that the Welling et al paper has completely solved the problem of selecting interesting low-dimensional subspaces in Gaussian distributed data. Note quite true. There are still challenges with XCA, as there are with PCA. For example, we have not said how we choose the total number of extreme components
Another challenge that is particularly relevant for high-dimensional data is the question of whether we will see distinct groups of principal and minor component sample covariance eigenvalues at all, even when we have distinct groups of population covariance eigenvalues. I chose very carefully the settings used to generate the simulated data in the example above. I ensured that we had many more samples than features, i.e. 
However, in PCA when we have 

Footnotes
- I have used the usual divide by
Bessel correction in the definition of the sample covariance. This is because I have assumed any data matrix will have been explicitly mean-centered. In many of the analyses of PCA the starting assumption is that the data is drawn from a mean-zero distribution, so that the sample mean of any feature is zero only under expectation, not as a constraint. Consequently, most formal analysis of PCA will define the sample covariance matrix with a
factor. Since I have to deal with real data, I will never presume the data been drawn from population distribution that has zero-mean and so to model the data with a zero-mean distribution I will explicitly mean-center the data. Therefore, I use the
definition of the sample covariance. Strictly speaking, that means the various theories and analyses I discuss later in the post are not applicable to the data I’ll work with. It is possible to modify the various analyses to explicitly take into account the mean-centering step, but it is tedious to do so. In practice, (for large
-
Hotelling, H. “Analysis of a complex of statistical variables into principal components”. Journal of Educational Psychology, 24:417-441 and also 24:498–520, 1933.
https://dx.doi.org/10.1037/h0071325 -
Oja, E. “Principal components, minor components, and linear neural networks”. Neural Networks, 5(6):927-935, 1992. https://doi.org/10.1016/S0893-6080(05)80089-9
-
Luo, F.-L., Unbehauen, R. and Cichocki, A. “A Minor Component Analysis Algorithm”. Neural Networks, 10(2):291-297, 1997. https://doi.org/10.1016/S0893-6080(96)00063-9
-
See for example, Williams, C.K.I. and Agakov, F.V. “Products of gaussians and probabilistic minor components analysis”. Neural Computation, 14(5):1169-1182, 2002. https://doi.org/10.1162/089976602753633439
© 2025 David Hoyle. All Rights Reserved
