
TL;DR: Forecasting is a process, not just a forecasting model. The over-whelming majority of textbooks will teach you how to build a particular type of forecasting model, but not about how, when and where to use a forecasting process. These things are often learnt only through experience. In this series of blog posts I detail what I have learnt about building forecasts and the forecasting process, through 10 years of commercial Data Science roles. The main takeaways – before you build any forecasting models think long and hard about why you need a forecast, what you are going to do with it, at what granularity and over what time horizon is the forecast needed – long-range forecasting is very different from short-range forecasting. You’ll always need some human involvement in the forecasting process even when using automated short-range forecasts, where it is still advisable to include a human oversight step in the decision making process. The longer the range of the forecast, the more human involvement is advisable.
Why forecast?
Almost all my Data Science roles in the commercial sector have been focused on some form of forecasting – from my first role outside of academia, where I was building long-range ‘stress-testing’ models for the UK’s largest retail bank, through building models that predicted the website clicks for AutoTraderUK in response to a TV advertising campaign, to the demand models I build at dunnhumby to forecast demand for the world’s largest grocery retailers. The focus on forecasting is perhaps no surprise. The ultimate use of the models in business is to help optimize some aspect of the business, be it helping determine the correct Tier 1 capital required to underpin the bank’s risk-weighted-assets, or to determine the best mix of TV channels and timings given a TV marketing budget, through to determining the optimal prices for products in a supermarket category. In all these examples it is the future performance of the business that we want to optimize. The use of forecasting models for business optimization is very much at the ‘prescriptive’ end of the Gartner analytics ascendency staircase. Businesses that use Data Science and ML models in this way are attempting to influence the future towards an outcome that is beneficial for them.
Why the need for this series of posts?
Not all businesses do use Data Science and Machine Learning in this way, or are able to, and so are less in control and more subject to the random winds of chance. Businesses that use forecasting models to optimize business operations tend to be both data and analytics mature. Typically, they have been using analytics in this way for a long time. It is not a new endeavour for those businesses. For other businesses that are new to forecasting there will be a temptation to believe that learning to forecast just requires learning the various forecasting techniques. During my various commercial roles I obviously had to learn the technical details of various forecasting techniques – ARIMA, Holt-Winters, etc. BUT….this article is not another introduction to how to use those various techniques to build models – there are plenty of excellent textbooks and online educational resources that will show you how to do that better than I can1. Instead, this is a series of blog posts about what I have learnt about forecasting along the way. Things which typically aren’t explained in the technical textbooks or technical online articles. Some of these things I’ve learnt the hard way – by making mistakes. Other things I have learnt after the forecast models have been built – when the real challenges of utilizing the models for the actual use case emerge.
Overall, the focus is on how to use forecasting, not how to build specific forecasting models. It will be on understanding what forecasting can do, where you should use it, what it can’t do, and how to get the best out of the forecasting process. I’m going to break this down into a series of 3 posts,
- Part1: What is forecasting? What can forecasting be used for?
- Part2: How to organize a forecasting process. What to do and what not to do.
- Part3: Links to resources and further reading.
Part 1
What is forecasting?
In this era of machine learning and AI can’t we just regard forecasting as just another form of prediction, and forecasting models should be constructed and interpreted just like any other machine learning model? The answer is no.
Forecasting vs Prediction
The high-level distinction between forecasting and prediction is the temporal element. When we forecast we are extrapolating into the future. When we build a predictive model we are usually interpolating within the training set from which the model has been built.
The term ‘projection’ is also used when talking about forecasting. Some organizations, such as the International Panel on Climate Change (IPCC) refer to a projection as a forward looking prediction under a particular scenario, whilst a forecast is the projection (scenario) that is considered most likely.
This also highlights that forecasts acknowledge the inherent element of uncertainty within them. Nate Silver in his book, ‘The Signal and the Noise’ notes that some fields such as seismology strongly emphasize this aspect, distinguishing,
A prediction is a definitive and specific statement about when and where an earthquake will strike…whereas a forecast is a probabilistic statement, usually over a longer timescale.
Nate Silver
Nate Silver states that, ‘The United States Geological Survey’s official position is that earthquakes cannot be predicted. They can, however, be forecasted’ – more details from the USGS here.
Recognizing the importance of the probabilistic nature of forecasts, many modern forecasts are now built directly from probabilistic models, with the uncertainty communicated, for example visually through the use of fan charts.
It’s about time
The temporal element of forecasting is key. It impacts two important aspects of any forecasting model we construct – i) The nature of the variables used in the forecasting model, ii) The time-horizon over which we forecast and what we can use those forecasts for. Let’s look at those two aspects.
Endogenous vs exogenous factors
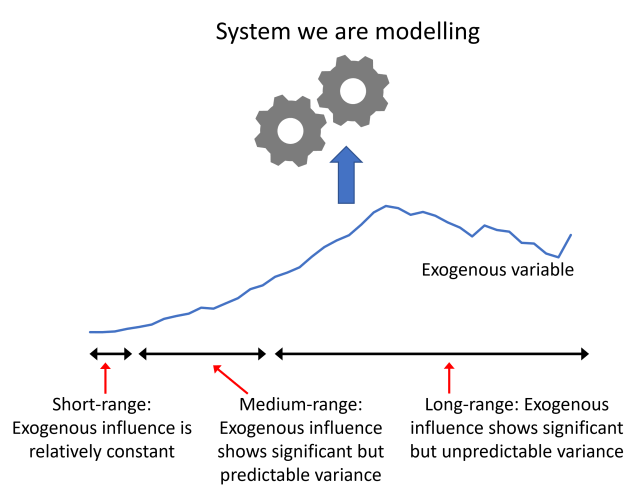
The temporal element of forecasting means it naturally involves trying to model and/or understand how a system evolves. The factors that influence that evolution can be internal to the system itself -what we call endogenous factors. These are variables that are determined or created by, or emerge from the system itself. An endogenous variable could be as simple as the lagged response variable itself. Other factors that can influence a system’s evolution are external to the system – what we call exogenous factors – such as the broader macro-economic climate when modelling the short-term dynamics of demand for goods or services in a small geographical region.
Forecast horizon
There are multiple temporal components/dimensions/concepts we may need to consider when building a forecasting model,
- The time-period used to train a forecasting model.
- The time-period over which the forecasting model is tested.
- The temporal granularity at which the forecasts are made, e.g. daily, weekly, monthly, etc.
- The time increments we use when advancing training/testing windows during the evaluation of the forecasting model.
- The time increments we use that set the frequency of the forecasting process when deployed.
- The time gap between when the forecasts are made and the date of the first forecast period, i.e., the gap between when the forecasts are made to when they are used.

Some of these concepts are illustrated in Figure 1 above, but perhaps the most important temporal component, and the one I want to focus on, is the length of the forecast horizon – how far into the future are we attempting to forecast? That is, are we making forecasts for the short-term, medium-term, or long-term. The forecast horizon is strongly linked to what a forecast model can be used for (or should be used for), and how it is used. More specifically,
- The appropriateness of different forecasting models and techniques is different over the different horizons.
- The accuracy of a forecasting model is different over different horizons.
- The factors or variables that influence the response variable being forecasted differ over different horizons.
- Even how the system being forecasted responds or evolves can be different over different horizons.
The net effect of all this is that the uses of forecasting are and should be different over different forecast horizons. So how do we define the forecast horizon? What defines a short-term horizon, versus a medium-term or long-term horizon? Ultimately, those concepts should be defined in terms of the characteristics or response of the system being forecast, and not the forecasting technique used.
However, there is no universally agreed definition of short-range versus long-range, as this discussion on CrossValidated testifies to. Below I’ll give my own definition and discuss in detail what distinguishes a short-range forecast from a medium-range or long-range forecast. As well as giving a definition based upon the dynamical characteristics of the system being forecasted and the factors that influence it, I’ll also give a second practical definition based upon how we intend to use the forecasts.
Short-range forecasts:
At a trivial level a short-range or short-term forecast is a forecast of the system we are interested in, but over a short period into the future – yes, a very unhelpful definition. So, what precisely defines short-term? It is more helpful to realize that what we mean by ‘short-term’ can vary from system to system. By short-term, we ultimately imply that we expect the behaviour of the system in the immediate past to be reasonable guide to its behaviour in the short-term future – we don’t expect to frequently see massive changes in level of the response variable, and the recent historical values of the response variable alone can enable us to produce a decent forecasting model. We are in the realm where ARIMA models do well. Over a short-term horizon the influence of exogenous variables has not yet begun to kick in, primarily because the important exogenous variables have not changed significantly – they are effectively constant – on these short-term timescales. For a high-street retailer interested in forecasting how many items they will sell, short-term may mean a few days ahead and up to two weeks ahead, whilst for a financial trader involved in ultra-high frequency trading, short-term is measured in milli-seconds and up to only a second or so. For a system whose dynamics are almost entirely endogenous, or systems whose exogenous influences evolve on timescales of years, e.g. climate systems, then short-term can be measured in multiples of years.
The fact that over a short-term horizon any exogenous influences may not vary illustrates that over different forecast horizons the dynamics of our system can be very different. Over short timescales the dynamics is endogenously controlled, over long timescales the dynamics is exogenously controlled.
In complex systems the dynamics over short and long timescales may be different for reasons other than just how the forecast horizon timescale compares to the timescale on which the exogenous influences vary. In complex systems we are likely to have multiple endogenous timescales defined or emergent. This is particularly true for economic systems and we see it in how those systems respond to a shock or a perturbation. Economists have a rule of thumb – in the short-term people are price inelastic (price-insensitive)2, meaning that after a change to a economic system, e.g. supply chain shocks, consumers may not have had time to adapt their behaviour to the new circumstances or the new prices/information available, and so still purchase in a similar manner to before even though prices may have risen. Over longer timescales, people adapt their behaviour – they find cheaper substitutes for the now more expensive item they used to purchase, or they find cheaper suppliers, and so consumers become more price-sensitive again over longer timescales.
The short-term horizon is defined by the shortest timescale process that has an appreciable/relevant influence on the response variable. In our system of interest there may be both exogenous and endogenous processes, and so timescales defined exogenously and endogenously. In a complex system, we will have multiple endogenous timescales, possibly varying by orders of magnitude.
This economic example also highlights that in complex systems and over long timescales we should probably regard everything as ultimately being endogenous due to the degree of inter-connectedness of the various sub-systems. Or in other words, no sub-component of the complex system can be considered on its own as a closed system or independent of other sub-systems, and we should always study the complex system as a whole – but very likely with a lot of simplifying assumptions.
Over the short-term we would expect a forecast to be accurate, or rather capable of being accurate. This doesn’t mean a short-term forecast can’t be massively inaccurate; we could have a extraordinary event and perturbations occur after the the forecast was made, i.e., an assumption that we are forecasting a stable system (a stationary process in statistical language) may turn out to be incorrect due to circumstances that could not have possibly been foreseen – think of a retailer making supply chain forecasts four or six weeks prior to the stock-piling panics that occurred as a consequence of the first Covid-19 lockdowns. Or it may simply be the case that the short-range forecasting model has been poorly built.
Putting unforeseen circumstances and model building competence aside, we would expect a short-range forecast to be reasonably accurate. It can be used for making accurate predictions for very specific scenarios. In contrast, a long-range forecast cannot. This gives us a second practical means of defining forecast horizon. Practically, short-term means the time horizon over which we can use the forecasting model for making detailed specific predictions. Note the emphasis on the word ‘use’. The use-case/business model will define the level of accuracy we require and so can effectively define what is short-range and what is long-range. The recent example of Zillow which exited from US house price forecasting is a case point – see here, here, and here for more detailed discussions. Zillow was using forecasting models over time horizons for which the accuracy was not sufficient to support the particular business model. Zillow was effectively relying on long-range forecasts for detailed predictions, even though the time horizon of 6months ahead may have appeared to be short-term.
The Zillow example illustrates again the difficulty in forecasting complex systems such as markets, particularly if actions taken on the back of the forecast are intended to be part of the market making process. It highlights that perhaps for complex systems we should regards almost all forecasts as long-range.
Medium-range forecasts:
As you might have guessed we can define a medium-term forecast as a forecast over a horizon over which any exogenous influences begin to show significant variation. This is true also for a long-range forecast, but for a medium range forecast horizon we may have a reasonable idea what the values of those exogenous influences may be, or we may even be in control of them, for example they may correspond to actionable variables such as marketing activity variables3. For typical business use-cases medium-range can mean anything from 3-6months out to as much as 18months in the future.
Because exogenous influences start to show significant variation, they can’t simply be absorbed into the intercept of any model, and the typical modelling techniques used are of the form, ‘technique A + X’, meaning that we include the exogenous variables X much like we would when building a standard regression model. Over the medium-term techniques such as ARIMA+X and SARIMA+X are useful.
Long-range forecasts:
By contrast to the definition of what constitutes short-range and medium-range forecasts, a long-range forecast is a forecast over a time-horizon in which exogenous factors have a significant influence and display a significant variance. This could be, for example, macro-economic factors evolving through several business cycles. For the stress-testing models I had to build we were interested in forecasting bank-loan default rates with unemployment rate and central bank base-rate as inputs into the forecasting model. The models were used to produce forecasts with a 5yr forecast horizon. Future unemployment and interest rates were obviously unknown, and so required their own additional forecasting models to predict them.
This macro-economic example highlights that the exogenous influences are themselves subject to variation that is difficult to know in advance. Long-range forecasts have an additional element of uncertainty that increases the final uncertainty of our end forecasts – namely that we probably don’t know all of the inputs to our main forecasting model to a high degree of accuracy. To a large extent this is to be expected. We are forecasting multiple years into the future. In that time many unforeseen circumstances can play-out, e.g., a referendum to leave a major trading block not going the way many people expected, or a global pandemic occurring.
Forecasting exogenous inputs, which encapsulate the influence of national and international contexts, can only be suggestive at best – a reflection of what we think might happen to those exogenous variables, all other things being stable. But….major random, global events do happen. Since we cannot always confidently know what the true future values of the exogenous variable will be, a long-range forecast can only ever be viewed as a ‘what-if’ forecast – what would be the loan default rate if the macro-economic conditions were X. More importantly, a long-range forecast should only ever be used as a ‘what-if’. An individual, specific long-range forecast shouldn’t be used to plan the operation of an organization, or its tactical response to a particular situation.
Does this mean long-range forecasting is useless? No! Far from it! Long-range forecasts won’t tell us what will happen, they tell us what might happen. And so long-range forecasting can be used to help an organization plan strategically. Okay, I hear you say that all forecasts only tell us what might happen, because all forecasts have some uncertainty. What I mean here is that, because the validity of a long-range forecast is dependent on the validity of the input values, we don’t even know if we are looking at an appropriate input scenario. So instead of producing a long-range forecast for a single input scenario, we should always produce a range of long-range forecasts from a range, or ensemble, of input scenarios. The output from an ensemble of long-range forecast then might reveal some behaviours we weren’t expecting, which the business or organization can plan an appropriate response or intervention to. Or alternatively, an ensemble or long-range forecasts may reveal that a particular output metric is largely insensitive to the input scenario, and therefore although we don’t know which scenario will ultimately play-out, we can be confident we know what the value of the metric will be. In our bank stress-testing example we may see that for a wide-ranging ensemble of input scenarios the long-range forecasts indicate that in all the scenarios considered a bank has sufficient capital to withstand the likely increased loan default rates. The bank executives may be confident that no significant capital needs to be raised to protect the bank against whatever the future holds.
You may scoff at last example given financial crisis of 2008, and you may question whether large banks are ever well-prepared for whatever economic future transpires. This may be true, but what it also highlights is that there should always be some discussion around whether the ensemble of input scenarios considered has been wide-ranging enough. Has a big enough stress been applied in the ‘what-if’ scenarios during the stress-testing exercise? This illustrates that long-range forecasting has a high degree of human involvement – to discuss both inputs and interpret outputs. How successful a long-range forecasting exercise is can depend on how an organization approaches it, and how the human contributions/element are brought into play – the excellent non-technical book, Uncharted by Margaret Heffernan discusses these points in depth – I discovered the book through this review by Tim Harford in the Financial Times.
Human involvement
The need for significant human involvement in producing some forecasts may be surprising in this era of Data Science and Machine Learning, but direct human involvement in producing forecasts has a long history. Prior to the development of rigorous time series analysis techniques such as ARIMA, this is to be expected. It is interesting to go back and read old articles such as this 1971 Harvard Business Review article on forecasting in business. Putting aside the very gendered language, it is intriguing to see the emphasis upon judgmental forecasting methods and forecasting by analogy. The value of judgmental methods has been re-discovered over the 15 years or so. Specific techniques such as the Delphi method are still widely used in fields as diverse as public transport planning and health. Techniques such as the Delphi method excel at getting a wide range of opinions and inputs to help reduce the uncertainty in understanding complex, many-layered situations. This is what humans are good at. It is also exactly the situation we often face when making long-range forecasts for complex systems. It is unsurprising then that the ability of humans to handle nuanced, ambiguous and complex scenarios is used in other techniques such as prediction markets and superforecasting.
What can we use forecasting for?
The challenges of making long-range forecasts illustrate that there can be markedly different uses of forecasting. Long-range forecasts are about reducing uncertainty through gaining qualitative and semi-quantitative understanding of what might happen. Short-range forecasts are about quantitative prediction of what we think will happen.
There are also other dimensions that differentiate what we can use forecasting for. Three of these that are worth highlighting are,
- Insight vs Prediction: This is illustrated well already above by the contrast between short-range forecasts and long-range forecasts, but it is also applicable to short-range or medium-range forecasts on their own. We can use a medium-range forecasting model to make predictions of what will happen in the future, but also to extract insight from the values of the parameters of that model as to what are the relative influences of the different factor upon that future.
- Prediction vs Prescription: In my opening paragraphs I highlighted the Gartner analytic ascendency staircase and how some companies have the data and analytic maturity that enable them to use computational forecasting models they’ve built in a prescriptive way – they are used to determine the optimal course of action as opposed to merely forecasting the current baseline scenario.
- Different levels of aggregation: When we build any predictive model we have to decide upon the response variable we are going to model. This typically involves a choice about what level of aggregation we going to use – should we build models of individual units (e.g. consumers), groups of units (e.g. a cohort of customers), or the entire population/collection of units (e.g. the entire customer base of an enterprise)? Generally speaking, we should model at the lowest level of granularity at which we first expect to see a homogenous response over the time-horizon of the forecasting exercise. Think of the example of modelling the future default rate of a loans portfolio; if the portfolio is made up of a heterogenous mix of different customer (loan) segments whose response to economic conditions differs across the segments, then as we change the segment mix of that portfolio we will get very different forecast. Modelling the default rate of each homogenous segment separately will allow us to flex that segment mix when exploring different forecast scenarios, whilst modelling the default rate of the portfolio in a single model will not.
Summary:
Forecasting involves extrapolation into the future. This makes it different to other predictive models you might build – these typically involve interpolation within a training dataset. The granularity at which you model is important. Even more important is the horizon over which you are forecasting. A long-term forecast should only be used for exploring behaviour under a range of hypothetical scenarios, whilst short-term and medium-term forecasts can be used to make detailed predictions about specific and highly likely scenarios. Long-range forecasts inform strategic planning, short and medium-term forecast inform tactical responses. This means that when forecasting we should identify what kind of forecast we want and only then choose our forecasting technique appropriately.
In the next part of this series of blog posts I will cover some of the do’s and don’ts of forecasting. It won’t be about how to use a particular forecast model building technique. It will be about the common mistakes made – including ones I’ve made or I’ve seen made – so that you can avoid them (in the future).
Footnotes
- This very recent review by Petropoulos et al (to appear in International Journal of Forecasting) gives both a comprehensive coverage of the different forecasting techniques available and also a comprehensive set of case studies. The case studies illustrate the practice and challenges of forecasting in individual sectors and so touch in part on some of the issues I’ll be discussing. I’ll also be aiming to give broad general advice (not sector specific) on the practice of forecasting.
- See for example, Milgrom, Paul and Roberts, John. “The LeChatelier Principle.” American Economic Review, March 1996, 86(1):173-179.
- For the purposes of this blog and for simplicity I’m going to ignore the subtle distinction of whether price and marketing variables in demand models are exogenous or endogenous. I’m going to consider them here as exogenous since they are being imposed or set by the marketer or retailer. However, price drives demand and demand drives the price, so it is common to consider price to be an endogenous variable over longer timescales and within the more complex system consisting jointly of the retailer and the consumer.

Pingback: Part 2 – What does the future hold? : Using forecasting in a commercial environment – Hoyle Analytics
Pingback: Part 3 – What does the future hold?: Using forecasting in a commercial environment – Hoyle Analytics