
This is a post that I’ve been meaning to write for a while. Having worked on demand forecasting in the past, I was intrigued when I saw this paper posted on the arXiv pre-print archive from one of the research teams at Amazon.
Although it was obvious why Amazon would be interested in forecasting demand, I was intrigued that Amazon chose to use a state space model approach. About 6 months later I attended the ISBIS2018 conference, at which Lindsay Berry from Duke University presented this paper that also used a state-space model approach to modelling the demand for supermarket goods. I also subsequently became aware of this technical report from Ivan Svetunkov at Lancaster University’s Management School.
With three pre-prints on demand forecasting that all utilised a state-space modelling approach I thought it would be interesting to do a post summarizing the work from the Amazon team. I may get round to doing a further post on the other two pre-prints at a later date.
At this point it is worth explaining a bit about demand models in general. Demand models are statistical models that are usually built from 2-5yrs worth of historical sales data. A demand model enables us to forecast how many units of a product we will sell given the price of the product and a number of other variables. The models allow us to forecast a number of ‘what-if’ scenarios, e.g. what will happen to my sales if I reduce the product price by 20%? Ultimately, the demand model can enable us to determine what is the optimal price we should charge for a product depending on what business KPI we want to optimize. Some traditional approaches to demand modelling use a log-log model, with the log of the demand of an item being linear in the log of the price of the item. These models are of the Working-Leser type of demand models1,2. For goods with large demand volumes, a log-log model form will be a reasonable assumption as the natural quantum of demand (a single unit) is much smaller than the typical level of demand and so we can consider the demand of such goods as effectively being continuous random variables.
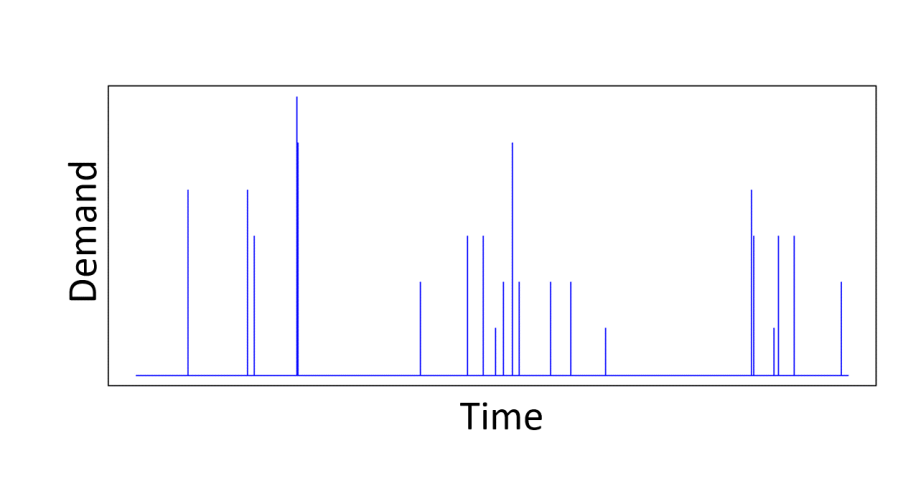
The actual problem the Amazon team tackled was forecasting of intermittent demand, i.e. for what are commonly called, ‘slow-moving goods’, whose pattern of sales are bursty. We might typically only sell, on average, less than say 10 units a week for these kinds of products. There may be no sales for a week or two, followed by a burst of sales concentrated in a few days. Snyder et al give a good modern review of the problem of intermittent demand forecasting3.
For such products, the traditional log-log type demand models can perform poorly, as we are dealing with products that sell only a few units per time period. However, there is no consensus approach to modelling such products, but this means it is an area ripe for novel and innovative methods. The paper by Seeger et al combines 3 interesting ideas,
- A multi-stage model – this means decomposing the modelling of demand into several models that cover different demand sizes. In this case separate models are constructed for when the expected demand is 0 units, 1 unit, and >1 unit.
- The combining of the multi-stage model with a state-space model. This has the effect of introducing exponential smoothing and hence some temporal continuity to the modelled demand.
- The use of a Kalman-filter approach to location of the mode when using a Laplace approximation to approximate a marginal posterior. This third innovation is the most technical, but, for me, also the most interesting.
The first of these innovations is not necessarily that much of a step-change. Other attempts to model slow-moving goods have also considered a mixture of distributions/processes to allow for the zero-inflation that one has in the weekly observed sales of a slow-moving good. Seeger et al use a three stage model, so that we have 3 latent functions,


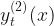
The second innovation is an interesting one. Whilst I had come across the use of self-excitation (Hawkes processes) to model the bursty behaviour of intermittent demand, I hadn’t seen temporal continuity enforced via a latent state contribution to the linear predictors of the mixture components. For demand greater than a single unit Seeger et al model the demand 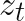

Here 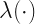

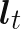

The latent variables 
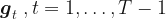
It is the marginalization over
The main task in a Laplace approximation is locating the maximum of the exponent of the integrand. Seeger et al do this via a Newton-Raphson procedure, i.e. expand the exponent to second order around the current estimate of the mode and then find the maximum of that second order approximation.
Consider a 1-dimensional example. Let 


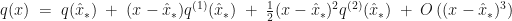
The updated estimate of

The schematic below depicts how the iterative Newton-Raphson procedure locates the maximum of a one-dimensional function.

The multi-dimensional equivalent update rule when we are maximizing a function 


where 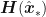

As Seeger et al are marginalizing the posterior over 



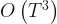

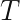
Seeger et al apply their methodology to a number of real-world scale datasets, for example to a ~40K item dataset with almost a year of historical data at the day-level. Overall run-times for the parameter learning are impressive (typically a few seconds for each of the separate demand model stages), though admittedly this is when running on a 150 node Spark cluster.
References
- Working, H. (1943) Statistical laws of family expenditure. J. Am. Statist. Ass., 38:43–56.
- Leser, C. E. V. (1963) Forms of Engel functions. Econometrica, 31, 694–703.
- Snyder, R., Ord, J., and Beaumont, A. (2012), Forecasting the intermittent demand for slow-moving inventories: A modelling approach. International Journal on Forecasting, 28:485-496
- Durbin, J. and Koopman, S. (2012), Time Series Analysis by State Space Methods. Oxford Statistical Sciences. Oxford University Press, 2nd Edition.
