
<TL;DR>
- The bisection algorithm is a very simple algorithm for finding the root of a 1-D function.
- Working out the number of iterations of the algorithm required to determine the root location within a specified tolerance can be determined from a very simple little hack, which I explain here.
- Things get more interesting when we consider variants of the bisection algorithm, where we cut an interval into unequal portions.
</TL;DR>
A little while ago a colleague mentioned that they were repeatedly using an off-the-shelf bisection algorithm to find the root of a function. The algorithm required the user to specify the number of iterations to run the bisection for. Since my colleague was running the algorithm repeatedly they wanted to set the number of iterations efficiently and also to achieve a guaranteed level of accuracy, but they didn’t know how to do this.
I mentioned that it was very simple to do this and it was a couple of lines of arithmetic in a little hack that I’d used many times. Then I realised that the hack was obvious and known to me because I was old – I’d been doing this sort of thing for years. My colleague hadn’t. So I thought the hack would be a good subject for a short blog post.
The idea behind a bisection algorithm is simple and illustrated in Figure 1 below.

At each iteration we determine whether the root is to the right of the current mid-point, in the right-hand interval, or to the left of the current mid-point, in the left-hand interval. In either case, the range within which we locate the root halves. We have gone from knowing it was in the interval ![[x_{lower}, x_{upper}]](https://s0.wp.com/latex.php?latex=%5Bx_%7Blower%7D%2C+x_%7Bupper%7D%5D&bg=ffffff&fg=111111&s=0&c=20201002)
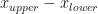


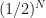




Strictly speaking we need to run for 
As a means of easily and quickly determining the number of iterations to run a bisection algorithm the calculation above is simple, easy to understand and a great little hack to remember.
Is bisection optimal?
The bisection algorithm works by dividing into two our current estimate of the interval in which the root lies. Dividing the interval in two is efficient. It is like we are playing the childhood game “Guess Who”, where we ask questions about the characters’ features in order to eliminate them.

Asking about a feature that approximately half the remaining characters possess is the most efficient – it has a reasonable probability of applying to the target character and eliminates half of the remaining characters. If we have single question, with a binary outcome and a probability 
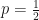

Dividing the interval unequally
When we first played “Guess Who” as kids we learnt that asking questions with a much lower probability
Let’s repeat the derivation but with a different cut-point e.g. 25% along the current interval bracketing the root. In general we can test whether the root is to the left of right of a point that is a proportion 

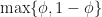
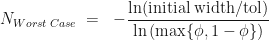
iterations to be guaranteed that we have located the root to within 
Now to determine the cut-point
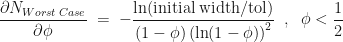
and

The minimum of 


That is the behaviour of the worst-case scenario. A similar analysis can be applied to the best-case scenario – we simply replace 
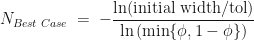
Here, the maximum of the best-case number of iterations occurs when 
That’s the worst-case and best-case scenarios, but how many iterations do we expect to use on average? Let’s look at the expected reduction in uncertainty in the root location after 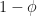

Using this as an approximation to determine the typical number of iterations, we get,
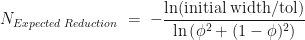
This still isn’t the expected number of iterations, but to see how it compares Figure 2 belows shows simulation estimates of 

For Figure 2 we have set 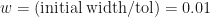
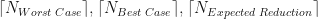

The expected number of iterations required, 
© 2022 David Hoyle. All Rights Reserved
