
<TL;DR>
This is part 2 of 3 about producing forecasts in real-world situations. Part 1 was more about the ‘what’ of forecasting, and specifically about different forecast horizons and how those different horizons shape how you do the forecast and what you can do with it. Part 2 is advice to help you avoid common mistakes when producing a forecast.
There are multiple distinct stages to producing and using a forecast. At the simplest level, we can list these different stages as,
- Planning a forecast.
- Executing a forecast.
- Assessing a forecast.
- Taking actions or decisions informed by a forecast.
- Updating a forecast.
- Deploying a forecasting process.
I have found that overwhelmingly the majority of mistakes I’ve made or seen made, are in the planning stage of producing a forecast. In fact, mistakes that I’ve seen in many of the later stages can ultimately be traced back to a failure to plan appropriately. That is, mistakes were made and spotted in one of the later stages, but if we’d thought about it properly, we could have anticipated that the error or issue would occur due to the way the forecasting process had been planned. This introduces our main takeaway,
Put a lot more time and effort into planning the forecasting process than you were initially going to do
</TL;DR>
Let’s get started. Since the majority of errors I’ve seen (and therefore opportunities for learning) are in the planning stage, that is where I’m going to focus most of my discussion. In fact, I am going to simplify the 6 stages outlined to above to just 3 broad areas of discussion,
- Mistakes to avoid when planning a forecast
- Mistakes to avoid when executing a forecast
- Mistakes to avoid when assessing a forecast
In each of those broad areas I’ll introduce a couple of common issues or mistakes that tend to get made, and also provide some hints on how to solve the issues or avoid the mistakes – the issues and solutions will be underlined to highlight them. I’ll also drop in a couple of real-world examples where I’ve seen these mistakes made, or where I made them myself.
Planning
Model Scope:
-
Issue: The initial information supplied to you is never sufficient to perform an appropriate forecast. This is an unwritten first rule of forecasting1.
 There will always be important/crucial things the person requesting the forecast has not told you – out of ignorance or absent-mindedness. This is the time to ask those extra questions, such as,
There will always be important/crucial things the person requesting the forecast has not told you – out of ignorance or absent-mindedness. This is the time to ask those extra questions, such as,- Why do you need the forecast? What problem are you actually trying to solve? More importantly, what decision are you trying to make using the information the forecast will give?
- How are you going to consume the forecast? Is it for insight – identifying the drivers that have the biggest impact on a medium-range outcome? Or is it for strategic planning? Or is it to be incorporated into a machine learning pipeline with an action automatically determined from the result of the forecast, e.g. changing an offer to a segment of customers.
- What is the forecast horizon over which you need the forecast?
- At what level of time granularity and segmentation do you need the forecast?
Solution: The answers to a) – d) above are inter-related, i.e. the answer to one may uniquely determine the answer to one of the others, but you should still ask each of those questions individually.
By understanding the scope of a system and how the forecast output is actually going to be used we avoid errors such as, failing to identify when the use-case does not justify the time and effort to develop the proposed forecasting model. A good example of this I’ve seen was a model developed for a national social housing charity that needed to predict the future costs of repairs to its housing stock. Due to various operational sensitivities, actions off the back of this prediction could only be taken at the regional level – the charity only needed to predict what the next month’s total repairs costs would be for each region in the country. But …the solution that was built used xgboost to predict the likely repair costs for each house in a region, given details about each house, and then simply aggregated the total predictions to regional level. Over the time horizons being forecasted the housing stock in each region was stable, so an equally accurate forecast could be obtained by using just the actual historical total monthly repair costs. As the historical total monthly repair costs just displayed seasonality and trend, a simple piece of SQL gave a prediction as accurate on a holdout sample as the xgboost based model.
Model Inputs:
-
Issue: Will you actually know all the input values and model parameter values at forecast time? Check that the values of all the exogenous variables will be known ahead of running the main forecasting model. If the exogenous variables you’ve used in your model include macro-economic quantities, their future values will not be known and you will either need a separate forecasting model for these, or their values will need to be part of the forecast scenario specification. This may be what you intended all along, but you’d be surprised how often someone builds a forecasting model and only afterwards realizes the challenges in specifying the input variables.
This problem can occur even in seemingly benign situations. For example, one mistake I’ve made in the past is using a set of dummy variables to model cohort fixed effects for a model of default rates in a loans portfolio. The only problem was that the loan book was still open – new cohorts were still coming onto the loan book – so to forecast the future default rate of the portfolio required assigning fixed effects to future, as yet unobserved, cohorts. In this instance we chose to make assignment of the future cohort effects part of the scenario specification – scenarios designated future cohorts as ‘high risk’, ‘medium risk’ or ‘low risk’ with the effects values being calculated from an appropriate centile of the historic cohort effects estimates. An alternative approach might have been to treat the cohort effects as random effects and when forecasting marginalize over the random effects of future cohorts. However, the two takeaways from this are, i) when planning a forecast model, think ahead to when you’re going to use it to produce the forecast and make sure you know how you’re going to obtain the input variables, ii) be cautious about including fixed cohort effects when producing forecasts for a changing cohort mix.
Solution: Mentally run through the forecasting process in your head, or on paper, before you start estimating your models. This will flush out issues with the model form or forecasting technique before you have committed to building them.
 Issue: Variables/features not included in the model in a sensible or correct form.
Issue: Variables/features not included in the model in a sensible or correct form.
I’ve a seen a model built by a marketing team that predicted the response to marketing activity. It was suspected that weather had an impact on how effective the marketing was. This was not an unreasonable hypothesis – when the summer weather is hot and sunny (not that common in the UK) most people want to be outside, in the park or at the beach, not paying close attention to some TV advert. The only problem was that ‘weather’ had been included in the predictive model as the average monthly temperature across the whole of England. There are so many things wrong with this,
- The temperature in England on a single day can vary hugely from one place to another. It can be sunny and 25°C in London whilst it is raining and 15°C in Manchester and hailing and 10°C in Newcastle. The England-wide average is a meaningless feature to try and reflect how likely anybody in a specific geography is to respond to marketing. The people in London will be relaxing in the park, ignoring the TV adverts, whilst people in Newcastle will be putting an extra jumper on and hunkering down in front of soap re-runs on the TV.
- In a similar vein, the use of a monthly average temperature is pointless. It was believed that the impact of weather on the marketing effectiveness was because of un-seasonal sunny weather over a few days. A monthly average will not reflect this. The monthly England-wide average temperature will reflect just seasonal patterns, not the particular effect the stakeholder was trying to understand.
- Temperature is the wrong feature to use here. Hours of sunlight may be better, since the hypothesis was that it was the un-expected very sunny summer weather that was reducing the effectiveness of the marketing. Even better, a feature that captured the presence of unusually hot, dry weather on summer days would be preferable to include in the model. Note that we have now moved from discussing temperature to talking about ‘dry’ summer days, i.e., the absence of any precipitation. When including weather effects in a model it can even be crucial to think what form of precipitation is relevant here. A former colleague told me about some work he’d done for a British mobile phone operator. The mobile company was interested in the impact of weather as they’d noticed that call volumes increased sometimes when there was precipitation. The analysis revealed that, yes, precipitation had an impact, but the form of the precipitation is hugely important. If it’s raining the impact is small, but lower the temperature so that the precipitation comes in the form of snow and the call volumes spike – everybody is phoning home or phoning work to say they are delayed because of snow-blocked roads or trains not running because of ice and snow on the rails. The lesson here is that the precise way in which weather affects our outcome of interest needs to be understood.
- Lastly, weather is a prime example of a variable that we won’t automatically know when it comes to producing the forecast. We may have a brilliant forecasting model, but we need to forecast the specific weather feature as well and we may not be able to do that accurately enough to get the benefit of our main forecasting model.
It was suspected that the person who built the model I’ve described just threw ‘weather’ into the model because they were told to. They simply got hold of the easiest or most accessible single weather variable they could find.
Solution: Spend time thinking through the form or particular variant of the feature you are putting into your forecasting model. Will it actually be capable of reflecting the actual effect you are trying to capture in your model? Is it at the right temporal and spatial granularity to be able to do that?
- Issue: Insufficient length of training data. Make sure the length of historical data you use to build your forecasting model is sufficiently long. How long is ‘sufficiently long’? Paul Saffo in this 2007 Harvard Business Review article on the 6 Rules For Effective Forecasting says that you should “look back twice as far as you look forward”. I would say you should look back even further. The point here, however, is not to give a precise rule for how much historical data you need for a given forecast horizon, but more to emphasize that the length of historical data you should use is always longer than you think. It should be sufficiently long enough to display several examples of the phenomena you need to capture with your model. To give an example – if you are modelling the effects of macro-economic climate on a financial metric, e.g., loan default rates, then you will want to include several business cycles and more importantly several recessionary periods in your historical training data. How far back in history is still a matter of subjective judgement – for example, was the recession resulting from the 2008 financial crash typical or atypical of the dynamics you want to model and forecast? This highlights two points, i) how far you go back in history can require a detailed discussion and review of the historical data – it is not simply, ‘let’s just include the last two recessions’, ii) you need to have a good idea of what sort of phenomena and/or dynamics you need to model for your forecasts to be representative of the scenarios you are trying to understand. Use the wrong data and the usefulness of your forecasting model may be short-lived.
 For long-range forecasts you’ll never really know in advance the full range of phenomena that your model needs to capture, as unpredictable and impactful phenomena are always capable of arising within the forecast horizon of a long-range forecast – what are called ‘Black-Swan’ events in parts of the popular science literature. In Part 1 we explained that by considering a very wide range of scenarios we mitigate against this, to a degree. But it means that a model used for long-range forecasting has to have captured dynamics and behaviour appropriate to a very wide range of phenomena – and that can require an awful lot of historical data. Anecdotally, I’ve seen that the length of training data required increases super-linearly with the length of the forecast horizon.
For long-range forecasts you’ll never really know in advance the full range of phenomena that your model needs to capture, as unpredictable and impactful phenomena are always capable of arising within the forecast horizon of a long-range forecast – what are called ‘Black-Swan’ events in parts of the popular science literature. In Part 1 we explained that by considering a very wide range of scenarios we mitigate against this, to a degree. But it means that a model used for long-range forecasting has to have captured dynamics and behaviour appropriate to a very wide range of phenomena – and that can require an awful lot of historical data. Anecdotally, I’ve seen that the length of training data required increases super-linearly with the length of the forecast horizon.
Solution: Think about the kind of phenomena or scenarios you want your model to be capable of forecasting. Does your training data contain adequate examples of such phenomena or scenarios? If yes, then you probably have enough training data. If no, then get additional appropriate training data, or shorten your forecast horizon (see Part I for why you should do this).
Model Form:
-
Issue: Using a complex or unusual generative modelling technique and believing you can just include the predictive features into the ‘model’ as you would when building a linear model or GLM.
I have seen an agent-based model used to attempt to forecast and identify emergent phenomena that it was believed would occur in response to a macro-economic change or shock. The agent-based simulation was used to mimic the microscopic interactions between the agents and their external environment – the general economy. A macro-economic variable, I think it was unemployment rate, was directly coupled to each agent’s propensity to spend. Lo-and-behold, when the unemployment rate increased the forecast showed that the total expenditure in the system went down. This was hailed as a new finding, showing emergent behaviour. No! It just reflected how the macro-economic variables had been included in the modelling. At this point over 12 months (at 3 FTE, I believe) had been expended on this project.
How the exogenous influences are coupled to a forecasting technique is critically important if we want to identify genuine emergent phenomena. Genuinely emergent phenomena are typically a global property of the system, often resulting from a global constraint. For example, in a physical system it could be a requirement to minimize the overall free energy of the system. In a financial system it could be a requirement to maximize total profit. Ideally, we should think about how the exogenous influences interact with these global constraints when including the exogenous variables in our modelling. If instead the exogenous variables are coupled directly to a metric we will later measure, we should not be surprised when that metric changes when the exogenous variables do.
Solution: The more complex the technique used you more you’ll need to think about how you put the predictive features into the ‘model’.
-
Issue: Computational optimization of forecast model outputs will exploit the weaknesses in your model. Be aware of the potential future downstream uses of your forecasting process. The forecasting technique you’ve used may not be robust enough to support likely (and anticipatable) downstream uses. It is likely, you’ve set up your forecasting process as an automatable, reproducible codebase. That codebase can then be included in a downstream automated process, such as finding the optimal value of one the actionable input variables. The optimization process will optimize the output of the forecasting model and because forecasts are, almost by definition, ‘out-of-sample’, there is the potential for the optimization process to drive the model to a region of the input space where the model output is non-sensical. This is because the optimization process does not know any better – we have not ensured that the forecasting model output has sensible and credible behaviour for all scenarios or for all sets of input values. To do this we need to build sensible structural constraints or principles into our forecasting model. Such constraints or principles usually come from domain knowledge, e.g. from economic principles when building forecasting models that include macro-economic inputs. These constraints or principles represent assumptions – we are assuming that our system of interest will or should obey classical economic principles. If those assumptions are incorrect, we will be guilty of produced a biased forecast. How do we know when to include such constraints or principles? We don’t know precisely, but we can think before constructing the forecasting model whether the benefits of including them outweigh the dis-advantages, and we are forewarned as to the potential bias. The main point here is, again, think and plan.
Solution: Understand if you will always be in control of the uses of your model. If not, then think whether your model needs to be robust to use-cases you can’t control.
Model Estimation:
-
Issue: The model estimation process is not set up to reflect what you’re actually trying to model. Use a cost-function that reflects the outcome you care about. When fitting a forecasting model, we will typically be minimizing some cost-function. Choose the cost-function appropriately. If forecast accuracy is going to be assessed using a different cost-function you may want to rethink the cost-function you use for fitting. Or in simple terms, fit your model to optimize the outcome you actually care about.
Solution: Think through each step of the proposed estimation process. Is it ideal for the thing you’re trying to capture.
Execution
-
Issue: How do you gauge whether your forecast is credible? Always run a baseline calculation or baseline scenario. For a short-range forecast you may have characterized very precisely the scenario you wish to predict, but your baseline scenario can still be something like a Business-As-Usual (BAU) scenario. For long-range forecasting, you can also use a BAU scenario as your baseline scenario but the definition of BAU may be more subjective and contain significant movement in exogenous influences – although it probably won’t be what you consider to be the most extreme scenario. The main benefit of running a baseline scenario is that it allows you to compute realistic ‘deltas’ even if there are far-from-perfect assumptions in your forecasting methodology. Remember the quote from George Box – ‘All models are wrong, but some are useful.’ The skill as a Data Scientist/Statistician is in knowing how to extract the useful insight and information from a ‘wrong’ model. With a baseline calculation you can compute how much worse or better the outcome is under scenario X compared to the baseline scenario. As a human you may then have a feel for what is incorrect in the baseline calculation and correct it or down-weight it. The model based estimate of the delta between scenario X and baseline scenario can then be applied to the human corrected baseline.
Solution: Running a baseline scenario where you have a more intuitive feel for how the system responds will help you assess any other scenario.
-
Issue: We have a forecast but not a quantitative measure of how confident we are with it. Always produce measures of uncertainty, e.g. confidence intervals for your forecasts. There is limited
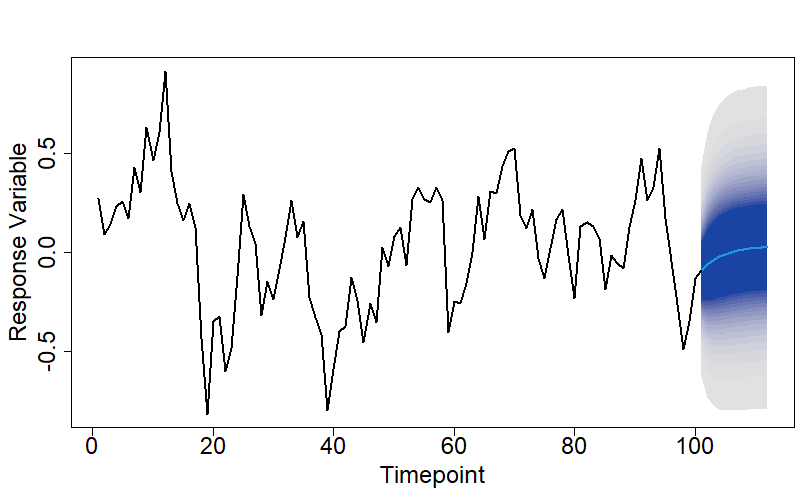 value in just a point estimate. How sensitive is that estimate to the stochastic component of the response variable dynamics? Then on top that we have uncertainty in the forecast due to parameter uncertainty and potentially also input uncertainty. Sensitivity analysis can help us quantify the impact on the forecast from both parameter uncertainty and input uncertainty, so that we can identify which we need to improve most. Don’t assume that just because values of exogenous variables have been specified for the forecast scenario that they are accurate. Forecast scenarios that are, upfront, specified very precisely can still be mis-specified or specified inappropriately, or even subject to change – it is not unusual for a company to execute a different BAU scenario to what they said they would at the time the forecast was produced.
value in just a point estimate. How sensitive is that estimate to the stochastic component of the response variable dynamics? Then on top that we have uncertainty in the forecast due to parameter uncertainty and potentially also input uncertainty. Sensitivity analysis can help us quantify the impact on the forecast from both parameter uncertainty and input uncertainty, so that we can identify which we need to improve most. Don’t assume that just because values of exogenous variables have been specified for the forecast scenario that they are accurate. Forecast scenarios that are, upfront, specified very precisely can still be mis-specified or specified inappropriately, or even subject to change – it is not unusual for a company to execute a different BAU scenario to what they said they would at the time the forecast was produced.
Solution: Quantify the impact on a forecast from all the major sources of uncertainty. Doing so is essential for framing and qualifying any decisions or actions taken on the back of the forecast output.
-
Issue: Distinguishing outputs from different forecasts gets messy when you have lots of them. Create a system for time-stamping forecast outputs, the associated input data and meta-data and also the codebase used to produce the forecast. This creates a disciplined process for running, re-running, and changing forecasts whilst knowing which run produced which forecast. You’ll be surprised how often you’ll end up asking yourself questions similar to , ‘now, did I include 5 or 6 years of training data and was it a 2month gap between the end of the training data and the beginning of the forecast horizon?’ Set-up a system to accurately capture what each forecast used, did, and what it was about.
Solution: Set up a system from the outset for timestamping and logging your forecast outputs along with the details on the inputs.
Assessment
-
Issue: How do you assess the accuracy of your forecasting method if the inputs may also be uncertain? If your forecasting model includes an input feature that itself is forecasted, then always perform holdout tests on your model with and without perfect hindsight.
- Testing with perfect hindsight is when we perform the holdout test using the actual observed values of all the input features.
- Testing without perfect hindsight is when we perform the holdout test using the forecasted values of any input features that need to be forecasted when actually running in production.
The clear value of performing the two different versions of the holdout tests is that it helps identify where the biggest bottleneck in forecast accuracy is. There is no point in trying to further improve a main forecasting model that is already accurate, say over a 1 year time horizon, if it is only accurate if we know all the inputs precisely and our forecasts of one of the input features is woeful – put the effort into improving the feature forecasting model.
Solution: Assess holdout forecast accuracy with and without perfect hindsight on the input variables.
-
Issue: How do know whether your complex forecasting technique is adding any value? Always run a baseline technique when assessing holdout accuracy. This is true of any use of machine learning. When building predictive classification models we often build a simple classifier, such as a naïve Bayes classifier, to provide a baseline against which to judge our more complex and sophisticated models and to check that the extra complexity is warranted. Similarly, when producing a forecast for a scenario using our chosen forecasting technique, we should include the forecast from a much simpler technique, such as exponential smoothing. In fact, this commentary, in the International Journal of Forecasting, on the recent M5 forecasting competition suggests 92.5% of the time you won’t beat a simple exponential smoothing model.
Solution: Include a simple baseline forecasting technique.
-
Issue: Over confidence in the forecast output.
Another of my favourite quotes from the famous statistician George Box,
‘Statisticians, like artists, have the bad habit of falling in love with their models.
George Box
I have been guilty of this myself. We become blind to the possibility that the output from a model can still be garbage even when we have provided high-quality input data. We believe that because we have circumvented the ‘garbage-in, garbage-out’ issue we must have a credible forecast because of the elegance and sophistication of the forecasting technique we have used. We have become seduced by the elegance of the forecasting technique. We have forgotten that ‘all models are wrong’. Well, if a model can be wrong, it can be completely and utterly wrong, and we should remember that. The first rule of forecast assessment – always doubt your forecast. Look at the forecast and see if you can explain to yourself why the forecast has that shape given the inputs.
Solution: Always be prepared to doubt and, if necessary, overrule your forecasts.
That’s Part 2. I hope it has been helpful. In Part 3 I’ll list some forecasting learning resources and tools that I’ve found useful.
Footnote 1: I seem to recall seeing this rule written in a blogpost or paper somewhere, but I’m unable to locate it. If anybody is aware of an original source for it, please let me know.
© 2022 David Hoyle. All Rights Reserved.
