
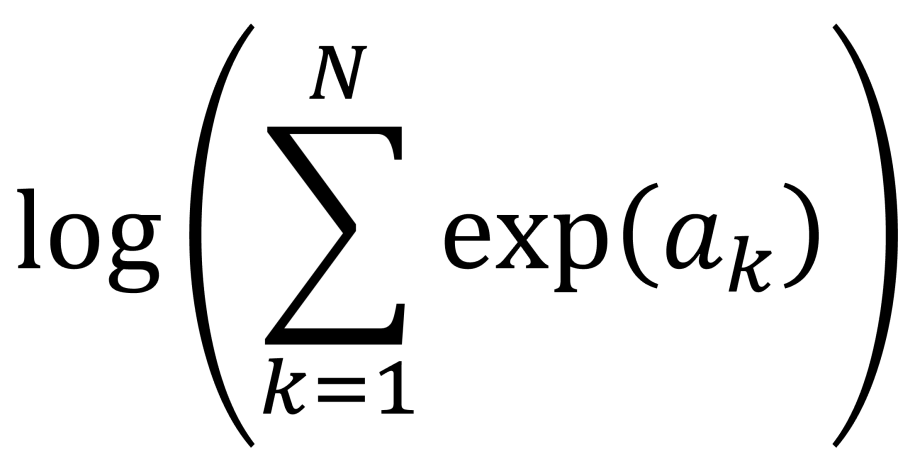
Summary
- Summing up many probabilities that are on very different scales often involves calculation of quantities of the form
. This calculation is called log-sum-exp.
- Calcuating log-sum-exp the naive way can lead to numerical instabilities. The solution to this numerical problem is the “log-sum-exp” trick.
- The scipy.special.logsumexp function provides a very useful implementation of the log-sum-exp trick.
- The log-sum-exp function also has uses in machine learning, as it is a smooth, differentiable approximation to the
function.
Introduction
This is the second in my series of Data Science Notes series. The first on Bland-Altman plots can be found here. This post is on a very simple numerical trick that ensures accuracy when adding lots of probability contributions together. The trick is so simple that implementations of it exist in standard Python packages, so you only need to call the appropriate function. However, you still need to understand why you can’t just naively code-up the calculation yourself, and why you need to use the numerical trick. As with the Bland-Altman plots, this is something I’ve had to explain to another Data Scientist in the last year.
The log-sum-exp trick
Sometimes you’ll need to calculate a sum of the form, 
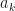

These sorts of calculations arise where you have log-likelihood or log-probability values
So what we need to do is exponentiate the
It depends on the relative values of the
If we have two values 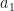





But how negative does 

In fact we can go further and approximate the whole sum by first of all identifying the maximum value in an array ![a = [a_{1}, a_{2}, \ldots, a_{N}]](https://s0.wp.com/latex.php?latex=a+%3D+%5Ba_%7B1%7D%2C+a_%7B2%7D%2C+%5Cldots%2C+a_%7BN%7D%5D&bg=ffffff&fg=111111&s=0&c=20201002)

The values 


The great news is that this “log-sum-exp” calculation is so common in different scientific fields that there are already Python functions written to do this for us. There is a very convenient “log-sum-exp” function in the SciPy package, which I’ll demonstrate in a moment.
The log-sum-exp function
The sharp-eyed amongst you may have noticed that the last formula above gives us a way of providing upper and lower bounds for the

The logarithm calculation on the right-hand side of the inequality above is what we call the log-sum-exp function (lse for short). So we have,

This gives us an upper bound for the ${\rm max}$ function. Since 

and so we have have a lower bound for the
Calculating log-sum-exp in Python
So how do we calculate the log-sum-exp function in Python. As I said, we can use the SciPy implementation which is in scipy.special. All we need to do is pass an array-like set of values
# import the packages and functions we needimport numpy as npfrom scipy.special import logsumexp# create the array of a_k values a = np.array([70.0, 68.9, 20.3, 72.9, 40.0])# Calculate log-sum-exp using the scipy function lse = logsumexp(a)# look at the resultprint(lse)
This will give the result 72.9707742189605
The example above and several more can be found in the Jupyter notebook DataScienceNotes2_LogSumExp.ipynb in the GitHub repository https://github.com/dchoyle/datascience_notes
The great thing about the SciPy implementation of log-sum-exp is that it allows us to include signed scale factors, i.e. we can compute,

where the values 

Here’a small code snippet illustrating the use of the scipy.special.logsumexp with signed contributions,
# Create the array of the a_k valuesa = np.array([10.0, 9.99999, 1.2])b = np.array([1.0, -1.0, 1.0])# Use the scipy.special log-sum-exp functionlse = logsumexp(a=a, b=b)# Look at the resultprint(lse)
This will give the result 1.2642342014146895.
If you look at the output of the example above you’ll see that the final result is much closer to the value of the last array element 

There is also a small subtlety in using the SciPy logsumexp function with signed contributions. If the substraction of some terms had led to an overall negative result, scipy.special.logsumexp will rerturn NaN as the result. In order to get it to always return a result for us, we have to tell it to return the sign of the final summation as well, by setting the return_sign argument of the function to True. Again, you can find the code example above and others in the notebook DataScienceNotes2_LogSumExp.ipynb in the GitHub repository https://github.com/dchoyle/datascience_notes.
When you are having to combine lots of different probabilities, that are on very different scales, and you need to subtract some of them and add others, the SciPy log-sum-exp function is very very useful.
© 2026 David Hoyle. All Rights Reserved
