

This year the UK’s Royal Statistical Society (RSS) held its annual international conference in Aberdeen between the 12th and 15th September 2022.
You may think that the society’s main conference doesn’t hold that much relevance for you as a Data Scientist. Yes, you have an interest in Data Science with a statistical flavour, but surely the main conference is all clinical trials analysis and the like, isn’t it? My job over the next 980 words is to persuade you otherwise.
Statistics is about the whole data life cycle
Go to the RSS website or look at an official email from the RSS and you’ll see that the RSS strapline is “Data | Evidence | Decisions”. This accurately reflects the breadth of topics covered at the conference – in the session talks, the posters, and the plenary lectures. Statistics is about data, and modern statistics now concerns itself with all aspects related to data – how it is collected, how it is analysed, how models are built from that data, how inferences are made from those models, and how decisions are made off the back of those inferences. A modern general statistics conference now has to reflect the full end-to-end lifecycle of data and also the computational and engineering workflows that go with it. This year’s RSS conference did just that.
A Strong Data Science focus
Over the three main days of the conference there were 7 specific sessions dedicated to Data Science, totalling 8hrs and 20mins of talks. You can see from the full list below the breadth covered in the Data Science sessions.
- Novel applications and Data Sets
- Introduction to MLOps
- The secret sauce of Open Source
- Data Science for Health Equity
- The UK’s future data research infrastructure
- Epidemiological applications of Data Science
- Algorithmic bias and ethical considerations in Data Science
On top of this there were Data Science topics in the 8 rapid fire talk sessions and in the 110 accepted posters. Example Data Science related topics included MLOps, Decentralized finance, Genetic algorithms, Kernels for optimal compression of distributions, Changepoint detection, Quantifying the Shannon entropy of a histogram, Digital Twins, Joint node degree estimation in Erdos-Renyi networks, Car club usage prediction, and Deep hierarchical classification of crop types from satellite images.
A growing Data Science presence
I’ve been involved with the conference board this year and last (Manchester 2021) and my perception is the size of the conference in increasing, in terms of number of submissions and attendees, the range of topics, and the amount of Data Science represented. However, I only have two datapoints here. One of those was just as the UK was coming out of its first Covid-19 lockdown, so will probably not provide a representative baseline. So I’m not going to stick my neck out too much here, but I do expect further increases in the amount of Data Science presence at next year’s conference.
Other relevant sessions
If like me you work primarily as a Data Scientist in a commercial environment, then there were also many talks from other Sections of the RSS that were highly relevant. The Business, Industry and Finance section had talks on Explainable AI, Novel Applications of Statistics in Business, and Democratisation of Statistics in GlaxoSmithKline, whilst the Professional Development section had talks on Linked Open Data, programming in R and Python, and the new Quarto scientific publishing system.
The Future of the Data Science Profession
Of particular relevance to Data Scientists was the Professional Development section’s talk on the new Alliance for Data Science Professionals accreditations of which the RSS is part. The session walked through the various paths to accreditation and the collaborative nature of the application process. This was backed up by a Data Science ‘Beer and Pizza’ event hosted by Brian Tarran (former Significance magazine editor and now RSS Head of Data Science Platform) and Ricky McGowan (RSS Head of Standards and Corporate Relations) who both explained some of the RSS long-term plans for Data Science.
Diversity of topics across the whole conference
Diversity of topics was a noticeable theme emerging from the conference as a whole, not just in the Data Science and commercial statistics streams. For me, this reflects the broader desire of the RSS to embrace Data Scientists and any practitioners who are involved with analysing and handling data. It reflects a healthy antidote to the ‘Two cultures of statistical modelling‘ divide identified and discussed by Leo Breiman many years ago.
For example, the range of plenary talks was equally impressive as the diversity of topics in the various sessions. Like many Data Scientists my original background was a PhD in Theoretical Physics. So, a talk from Ewain Gwynne on Random Surfaces and Liouville Quantum Gravity – see picture below – took me back 30 years and also gave me an enjoyable update on what has happened in the field in those intervening years.

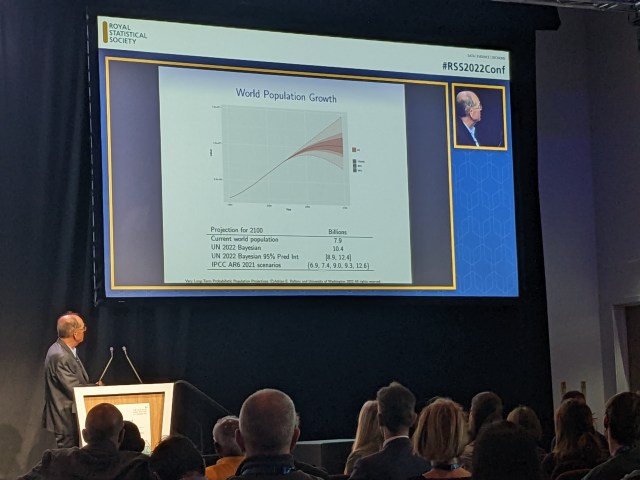
Other plenary highlights for me were Ruth King’s Barnett lecture on statistical ecology and Adrian Raftery’s talk on the challenges of forecasting world populations out to the year 2100 and as far as 2300 – see below.
A friendly conference
The conference is not a mega-conference. We not talking NeurIPS or ICML. It was around 600 attendees – big enough not to be too insular and focused only on one or two topics, but still small enough to be welcoming, friendly and very sociable. There were social events on every evening of the conference. And to top it all, it was even sunny in Aberdeen for the whole week.
I also got to play pool against the person who led the UK’s COVID-19 dashboard work, reporting the UK government’s official daily COVID-19 stats to the general public. I lost 2-1. I now hold a grudge.
Next year – Harrogate 2023
Next year’s conference is in Harrogate, 4th – 7th September 2023. I will be going. Between now and then I will be practicing my pool for a revenge match. I will also be involved with the conference board again, helping to shape the Data Science content. I can promise a wide range of Data Science contributions and talks on other statistical topics Data Scientists will find interesting. I can’t promise sunshine, but that’s Yorkshire for you.
© 2022 David Hoyle. All Rights Reserved

