

TL;DR: Having a high-level understanding of the mathematics of transformers is important for any Data Scientist. The two sources I recommend below are excellent short introductions to the maths of transformers and modern language models.
A colleague asked me, about two months back, if I could recommend any articles on the mathematics of Large Language Models (LLMs). They then clarified that they meant transformers, as they were primarily interested in the algorithms on which LLM apps are based. Yes, they’d skim read the original “Attention Is All You Need” paper from Vaswani et al, but they done so just after the paper came out in 2017. They were looking to get back up to date with LLMs and even revisit the original Vaswani paper. Firstly, they wanted an accessible explanation which they could use to construct a high-level mental model of how transformers worked, the idea being that the high-level mental model would serve as a construct on which to hang and compartmentalize the many new concepts and advances that had happened since the Vaswani paper. Secondly, my colleague is very mathematically able, so they were looking for mathematical detail, but the right mathematical detail, and in a relatively short read.
I’ve listed below the recommendations I gave to my colleague because I think they are good recommendations (and I explain why below as well). I also believe it is important for all Data Scientists to have at least a high-level understanding of how transformers, and the LLMs which are built on them, work – again I explain why, below.
The recommendations
What I recommended was one paper and one book. The article is free to access, and the book has a “set your own price” option for access to the electronic version of the book.
- The article is, “An Introduction to Transformers” by Richard Turner from the Dept. of Engineering at the University of Cambridge and Microsoft Research in Cambridge (UK). This arXiv paper can be found here. The paper focuses on how transformers work but not on training them. That way the reader focuses on the structure of the transformers without getting lost in the details of the arcane and dark art of training transformers. This is why I like this paper. It gives you an overview of what transformers are and how they work without getting into the necessary but separate nitty-gritty of how you get them to work. To read the paper does require some prior knowledge of mathematics but the level is not that high – see the last line of the abstract of the paper. The whole paper is only six pages long, making it a very succinct explanation of transformer maths that you can consume in one sitting.
- The book is “The Hundred-Page Language Models Book” by Andriy Burkov. This is the latest in the series of books from Burkov, that include “The Hundred-Page Machine Learning Book” and “Machine Learning Engineering”. I have a copy of the hundred-page machine learning book and I think it is ok, but I prefer the LLMs book. I think part of the reason for this is that, like everybody else I have been only been using and playing with LLMs for the last three years or so, whilst I have been doing Data Science for a lot longer – I have been doing some form of mathematical or statistical modelling for over 30years – and so I didn’t really learn anything new from the machine learning book. In contrast, I learnt a lot from the book on LLMs. The whole book works through simple examples, both in code (Python) and in terms of the maths. I semi-skim read the book in two sittings. The code examples I skipped, not because they were simplistic but because I wanted to digest the theory and algorithm explanations end-to-end first and then return to trying the code examples at a later date. Overall, the book is packed with useful nuggets. It is a longer read than the Turner paper, but can still easily be consumed in a day if you skip bits. The book assumes less prior mathematical knowledge than the Turner paper and explains the new bits of maths it introduces, but given the whirlwind nature of a 100-page introduction to LLMs I would still recommend you have some basic familiarity with linear algebra, statistics & probability, and machine learning concepts.
Why learn the mathematics of transformers?
Having to think about which short articles I would recommend on the maths of transformers and LLMs made me think more broadly about whether there is any benefit from having a high-level understanding of transformer maths. My colleague was approaching it out of curiosity, and I knew that. They simply wanted to learn, not because they had to, nor because they thought that understanding the mathematical basis of transformers was the way to approach using LLMs as a tool.
However, given the exorbitant financial cost of building foundation models and the need to master a vast amount of engineering detail, most people won’t be building their own foundation models. Instead they will be using 3rd party models simply as a tool and focusing on developing skills and familiarity in prompting them. So, are there any benefits then to understanding the maths behind LLMs? In other words, could I honestly recommend the two sources listed above to anybody else other than my colleague who was interested mainly out of curiousity?
The benefits of learning the maths of transformers and the risks of not doing so
The answer to the question above, in my opinion, is yes. But you probably could have guessed that from the fact I’ve written this post. So, what do I think are the benefits to a Data Scientist in having a high-level understanding of the mathematics of transformers? And equally important, what are the downsides and risks of not having that high-level understanding?
- Having even a high-level understanding of the maths behind transformers de-mystifies LLMs since it forces you to focus on what is inside LLMs. Without this understanding you risk putting an unnecessary veneer of complexity or mysticism on top of LLMs, a veneer that prevents you using LLMs effectively.
- You will understand why LLMs hallucinate. You will understand that LLMs build a model of the high-dimensional conditional probability distribution of the next token given the preceding context. And that distribution can have a large dispersion if the the training data is limited in the high-dimensional region that corresponds to the current context. That large dispersion results in the sampled next token having a high probability of being inappropriate. If you understand what LLMs are modelling and how they model it, hallucinations will not be a surprise to you (they may still be annoying) and you will understand strategies to mitigate them. If you don’t understand how LLMs are modelling the conditional probability of the next token, you will always be surprised, annoyed, and impacted by LLM hallucinations.
- It helps you understand where LLMs excel and where they don’t because you have a grounded understanding of their strengths and weaknesses. This makes it easier to identify potential applications of LLMs. The downside? Not having a fundamental understanding of the strengths and weaknesses of the algorithms behind LLMs risks you building LLM-based applications that were doomed to failure from the start because they have been mis-matched to the capabilities of LLMs.
- By having a high-level mental model of transformers on which to hang later advances in LLMs, you can more easily identify what is important and relevant (or not) in any new advance. The downside to not having this well-founded mental-model is that you get blown about by the winds of over-hyped LLM announcements from companies stating that their new tool or app is a “paradigm shift”, and consequently you waste time getting into the detail of what are trivial or inconsequential improvements.
What to do?
What should you do if you are a Data Scientist and I have managed to convince you that having a high-level understanding of the mathematics of transformers is important? Simple, access the two sources I’ve recommended above. Happy reading.
© 2025 David Hoyle. All Rights Reserved

 Eq.1
Eq.1
![[\frac{1}{x_{max}}, x_{max}]](https://s0.wp.com/latex.php?latex=%5B%5Cfrac%7B1%7D%7Bx_%7Bmax%7D%7D%2C+x_%7Bmax%7D%5D&bg=ffffff&fg=111111&s=0&c=20201002) so that the probability distribution of
so that the probability distribution of  is properly normalized. We’ll then take the limit
is properly normalized. We’ll then take the limit  at the end. For convenience, well take
at the end. For convenience, well take  to be of the form
to be of the form  , and so the limit
, and so the limit  .
.

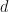 are of the form
are of the form  with
with  and
and  . So, the total probability of getting such a number is,
. So, the total probability of getting such a number is,
![{\rm{Prob}} \left ( {\rm{first\;digit}}\;=\;d \right ) = \frac{2k_{max}}{2\ln x_{max}} \left [ \ln ( d+1 ) - \ln d\right ]\;\;.](https://s0.wp.com/latex.php?latex=%7B%5Crm%7BProb%7D%7D+%5Cleft+%28+%7B%5Crm%7Bfirst%5C%3Bdigit%7D%7D%5C%3B%3D%5C%3Bd+%5Cright+%29+%3D+%5Cfrac%7B2k_%7Bmax%7D%7D%7B2%5Cln+x_%7Bmax%7D%7D+%5Cleft+%5B+%5Cln+%28+d%2B1+%29+-+%5Cln+d%5Cright+%5D%5C%3B%5C%3B.&bg=ffffff&fg=111111&s=0&c=20201002)
 , we get,
, we get,![{\rm{Prob}} \left ( {\rm{first\;digit}}\;=\;d \right ) = \frac{1}{\ln 10} \left [ \ln ( d+1 ) - \ln d\right ]\;=\;\log_{10} \left ( 1 + \frac{1}{d}\right )\;\;.](https://s0.wp.com/latex.php?latex=%7B%5Crm%7BProb%7D%7D+%5Cleft+%28+%7B%5Crm%7Bfirst%5C%3Bdigit%7D%7D%5C%3B%3D%5C%3Bd+%5Cright+%29+%3D+%5Cfrac%7B1%7D%7B%5Cln+10%7D+%5Cleft+%5B+%5Cln+%28+d%2B1+%29+-+%5Cln+d%5Cright+%5D%5C%3B%3D%5C%3B%5Clog_%7B10%7D+%5Cleft+%28+1+%2B+%5Cfrac%7B1%7D%7Bd%7D%5Cright+%29%5C%3B%5C%3B.&bg=ffffff&fg=111111&s=0&c=20201002)
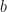 . This means that Benford’s Law is base invariant, and a similar derivation can be made for base
. This means that Benford’s Law is base invariant, and a similar derivation can be made for base 
 is in the set
is in the set  and the probability that the first digit has value
and the probability that the first digit has value  Eq.2
Eq.2

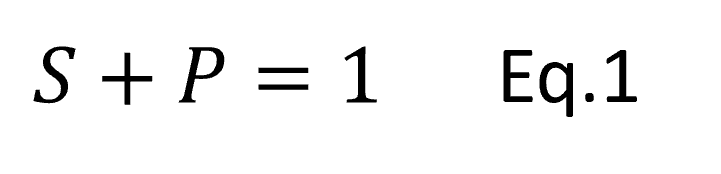






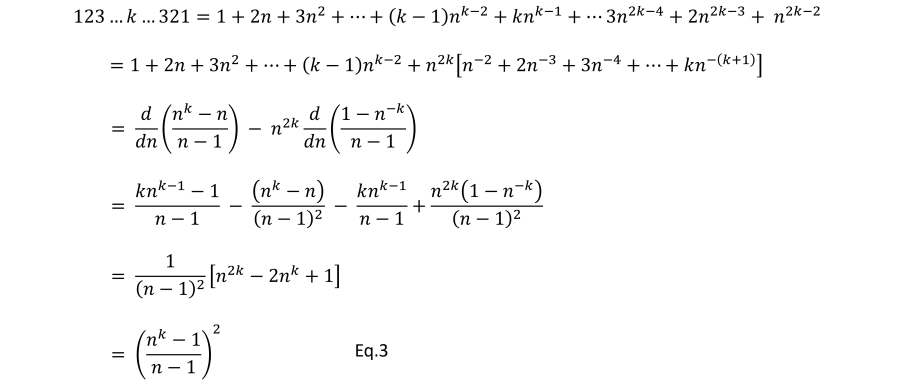

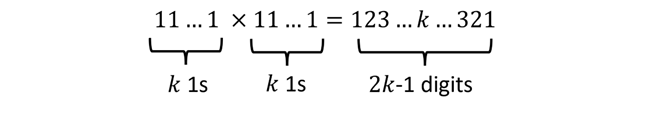




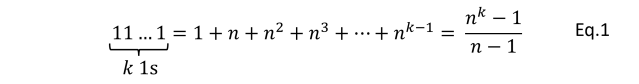

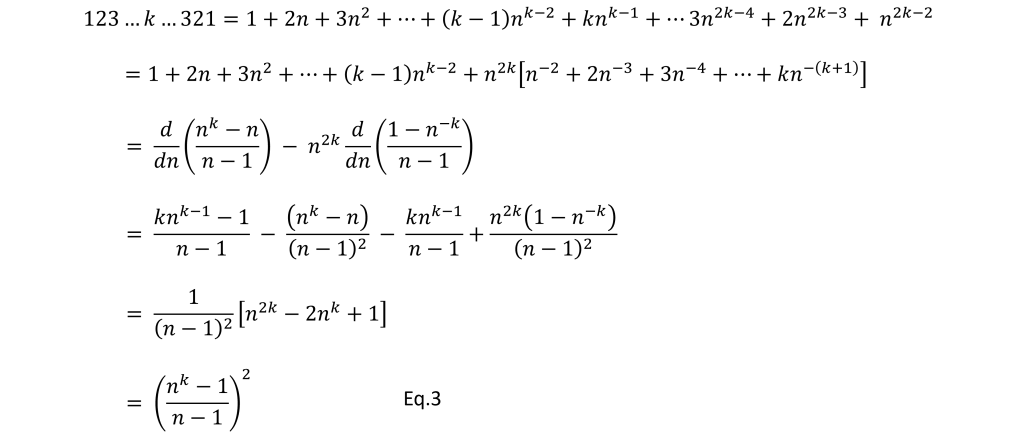




![[x_{lower}, x_{upper}]](https://s0.wp.com/latex.php?latex=%5Bx_%7Blower%7D%2C+x_%7Bupper%7D%5D&bg=ffffff&fg=111111&s=0&c=20201002) , which has width
, which has width 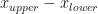 , to knowing it is in an interval of width
, to knowing it is in an interval of width  . So with every iteration we reduce our uncertainty of where the root is located by half. After
. So with every iteration we reduce our uncertainty of where the root is located by half. After  iterations we have reduced our initial uncertainty by
iterations we have reduced our initial uncertainty by 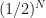 . Given our initial uncertainty is determined by the initial bracketing of the root, i.e. an interval of width
. Given our initial uncertainty is determined by the initial bracketing of the root, i.e. an interval of width  , we can now work out that after
, we can now work out that after  . Now if we want to locate the root to within a tolerance
. Now if we want to locate the root to within a tolerance  , we just have to keep iterating until the uncertainty reaches
, we just have to keep iterating until the uncertainty reaches 
 iterations. Usually I will add on a few extra iterations, e.g. 3 to 5, as an engineering safety factor.
iterations. Usually I will add on a few extra iterations, e.g. 3 to 5, as an engineering safety factor.
 of one of those outcomes, then the question that has
of one of those outcomes, then the question that has 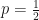 maximizes the expected information (the entropy),
maximizes the expected information (the entropy),  .
. along the current interval, meaning the cut-point is
along the current interval, meaning the cut-point is  . At each iteration we don’t know in advance which side of the cut-point the root lies until we test for it, so in trying to determine in advance the number of iterations we need to run, we have to assume the worst case scenario and assume that the root is still in the larger of the two intervals. The reduction in uncertainty is then,
. At each iteration we don’t know in advance which side of the cut-point the root lies until we test for it, so in trying to determine in advance the number of iterations we need to run, we have to assume the worst case scenario and assume that the root is still in the larger of the two intervals. The reduction in uncertainty is then, 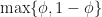 . Repeating the derivation we find that we have to run at least,
. Repeating the derivation we find that we have to run at least,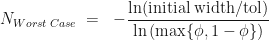
 .
.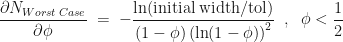

 is at
is at  , although
, although  is not a stationary point of the upper bound
is not a stationary point of the upper bound  with
with 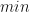 in all the above formula. That is, in the best-case scenario the number of iterations required is given by,
in all the above formula. That is, in the best-case scenario the number of iterations required is given by, 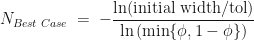
 .
. 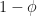 with probability
with probability 
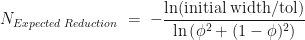
 plotted against
plotted against 
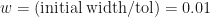 . Also plotted in Figure 2 are our three theoretical estimates,
. Also plotted in Figure 2 are our three theoretical estimates, 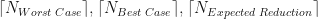 . The stepped structure in these 3 integer quantities is clearly apparent, as is how many more iterations are required under the worst case method when
. The stepped structure in these 3 integer quantities is clearly apparent, as is how many more iterations are required under the worst case method when  .
. , actually shows a rich structure that isn’t clear unless you zoom in. Some aspects of that structure were unexpected, but requires some more involved mathematics to understand. I may save that for a follow-up post at a later date.
, actually shows a rich structure that isn’t clear unless you zoom in. Some aspects of that structure were unexpected, but requires some more involved mathematics to understand. I may save that for a follow-up post at a later date.





