Summary
- Estimating the variance of a distribution when we have outliers can create a circular problem, particularly if we want to use the estimated variance in an algorithm to detect the outliers in the first place.
- If we are prepared to assume, that at most, a fraction
of our data are outliers, then we can use a trimmed-variance to estimate the population variance without having to explicitly identify the outliers.
- We incorporate a correction factor to make our variance estimate consistent with the parametric distribution we have assumed our data has been drawn from.
- The median absolute deviation from the median (MAD) also uses a similar idea and tends to have better performance (efficiency) for outlier-contaminated Normal data.
- Calculating the Normal-consistent MAD-based estimate of the standard deviation is ridiculously simple.
Introduction
This is one of those little hacks that I really like. So simple, so easy, and yet it solves a real problem. It solves a circular problem. How to estimate the standard deviation of a distribution from a sample of data, without being impacted by outliers when we haven’t yet identified which datapoints are outliers. We may even want to use that estimate of the standard deviation to help detect those outliers – in an appropriate algorithm that takes the sample size into account of course (see my previous Data Science Notes post What is an outlier?). It looks like we have a circular problem; the outliers affect the estimation of the standard deviation, but we can’t identify and deal with those outliers until we have calculated the standard deviation.
We can drop the data points from the tails of the sample to remove outliers. The trouble is the standard deviation relates to the spread of values in a distribution, i.e. it relates to the tails of the distribution. It looks like we are going to lose signal about the standard deviation if we do this.
If only there was a way to estimate a standard deviation from just the data values around the mean. That is, can we estimate the standard deviation from the data points that have come from the bulk of the distribution and not its tails? There is, if we are prepared to make a parametric assumption about the shape of the distribution. Once we make a parametric assumption about the shape, any datapoint gives us signal about the parameters of the distribution. And once we have signal about the parameters of the distribution we have signal about its standard deviation.
Theory
Let’s use the Normal distribution as an example. We know that the probability density is given by,

In Eq.1 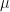
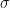
![\left [ -\sigma x_{5} + \mu , \sigma x_{5} + \mu \right ]](https://s0.wp.com/latex.php?latex=%5Cleft+%5B+-%5Csigma+x_%7B5%7D+%2B+%5Cmu+%2C+%5Csigma+x_%7B5%7D+%2B+%5Cmu+%5Cright+%5D&bg=ffffff&fg=111111&s=0&c=20201002)


If we calculate the 2nd moment of 
![\frac{1}{\sqrt{2\pi\sigma^{2}}}\int_{-x_{5} }^{x_{5}} x^{2}\,\exp \left ( -\frac{x^{2}}{2\sigma^{2}}\right )\, dx\;=\; 0.9\sigma^{2}\left [ 1 + \frac{2}{0.9}\Phi^{-1}\left ( 0.05\right ) \phi \left ( \Phi^{-1}\left ( 0.05 \right )\right ) \right ]](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7B%5Csqrt%7B2%5Cpi%5Csigma%5E%7B2%7D%7D%7D%5Cint_%7B-x_%7B5%7D+%7D%5E%7Bx_%7B5%7D%7D+x%5E%7B2%7D%5C%2C%5Cexp+%5Cleft+%28+-%5Cfrac%7Bx%5E%7B2%7D%7D%7B2%5Csigma%5E%7B2%7D%7D%5Cright+%29%5C%2C+dx%5C%3B%3D%5C%3B+0.9%5Csigma%5E%7B2%7D%5Cleft+%5B+1+%2B+%5Cfrac%7B2%7D%7B0.9%7D%5CPhi%5E%7B-1%7D%5Cleft+%28+0.05%5Cright+%29+%5Cphi+%5Cleft+%28+%5CPhi%5E%7B-1%7D%5Cleft+%28+0.05+%5Cright+%29%5Cright+%29%C2%A0%C2%A0%C2%A0%C2%A0+%5Cright+%5D&bg=ffffff&fg=111111&s=0&c=20201002)
In Eq.3 


Let’s denote our sample of data by the vector 
![s^{2} \simeq \sigma^{2}\left [ 1 + \frac{2}{0.9}\Phi^{-1}\left ( 0.05\right ) \phi \left ( \Phi^{-1}\left ( 0.05 \right )\right ) \right ]](https://s0.wp.com/latex.php?latex=s%5E%7B2%7D+%5Csimeq+%5Csigma%5E%7B2%7D%5Cleft+%5B+1+%2B+%5Cfrac%7B2%7D%7B0.9%7D%5CPhi%5E%7B-1%7D%5Cleft+%28+0.05%5Cright+%29+%5Cphi+%5Cleft+%28+%5CPhi%5E%7B-1%7D%5Cleft+%28+0.05+%5Cright+%29%5Cright+%29%C2%A0%C2%A0%C2%A0%C2%A0+%5Cright+%5D+&bg=ffffff&fg=111111&s=0&c=20201002)
A simple re-arrangement of Eq.4 gives us a means of estimating 
![\hat{\sigma}^{2}\simeq \frac{s^{2}}{\left [ 1 + \frac{2}{0.9}\Phi^{-1}\left ( 0.05\right ) \phi \left ( \Phi^{-1}\left ( 0.05 \right )\right ) \right ] }](https://s0.wp.com/latex.php?latex=%5Chat%7B%5Csigma%7D%5E%7B2%7D%5Csimeq+%5Cfrac%7Bs%5E%7B2%7D%7D%7B%5Cleft+%5B+1+%2B+%5Cfrac%7B2%7D%7B0.9%7D%5CPhi%5E%7B-1%7D%5Cleft+%28+0.05%5Cright+%29+%5Cphi+%5Cleft+%28+%5CPhi%5E%7B-1%7D%5Cleft+%28+0.05+%5Cright+%29%5Cright+%29%C2%A0%C2%A0%C2%A0%C2%A0+%5Cright+%5D+%7D&bg=ffffff&fg=111111&s=0&c=20201002)
There you have it. A simple way to estimate the standard deviation of a Normal distribution whilst excluding the smallest and largest 5% of values. If we want to exclude 
![\hat{\sigma}^{2}\;=\; \frac{s^{2}}{\left [ 1 + \frac{2}{1 - \alpha}\Phi^{-1}\left ( \frac{1}{2}\alpha\right ) \phi \left ( \Phi^{-1}\left ( \frac{1}{2}\alpha \right )\right ) \right ] }](https://s0.wp.com/latex.php?latex=%5Chat%7B%5Csigma%7D%5E%7B2%7D%5C%3B%3D%5C%3B+%5Cfrac%7Bs%5E%7B2%7D%7D%7B%5Cleft+%5B+1+%2B+%5Cfrac%7B2%7D%7B1+-+%5Calpha%7D%5CPhi%5E%7B-1%7D%5Cleft+%28+%5Cfrac%7B1%7D%7B2%7D%5Calpha%5Cright+%29+%5Cphi+%5Cleft+%28+%5CPhi%5E%7B-1%7D%5Cleft+%28+%5Cfrac%7B1%7D%7B2%7D%5Calpha+%5Cright+%29%5Cright+%29+%C2%A0%C2%A0%5Cright+%5D+%7D&bg=ffffff&fg=111111&s=0&c=20201002)
Practice
That’s the theory. How do we use this simple idea in practice? Like all simple but great ideas someone has already coded it up for you. In Python the trimmed variance of an array a of numbers can be calculated using the trimmed_var function in scipy.stats.mstats, as follows,
from scipy.stats.mstats import trimmed_vartrimmed_var = trimmed_var(a, limits=(0.05, 0.05), inclusive=(1, 1), relative=True, axis=None, ddof=1)
In the notebook DataScienceNotes5_TrimmedVariances.ipynb in the public GitHub repository github.com/dchoyle/datascience_notes, I have used the trimmed_var function to run a number of simulations. The plot below (Figure 1) shows the average estimated variance, averaged over 1000 simulation datasets, using the formula in Eq.6 and where I have used the scipy trimmed_var function to calculate 
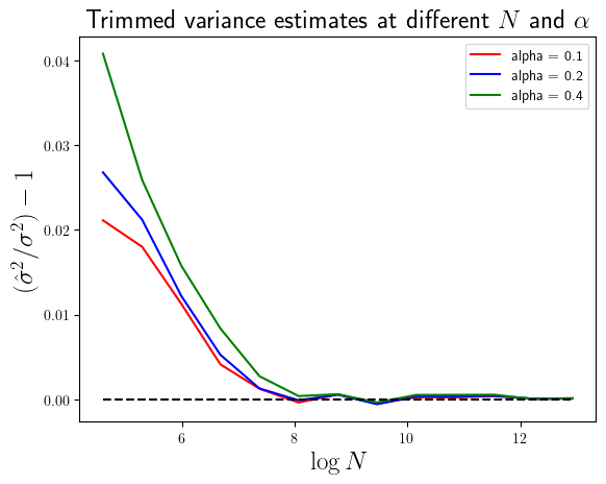
On the y-axis I’ve actually plotted the ratio of the average estimated variance to the true population variance (with which the data was generated) minus 1, so that it is easier to see how accurate the estimated variance is. A value of zero on the y-axis indicates a perfect estimate. You can see that as the starting sample size 



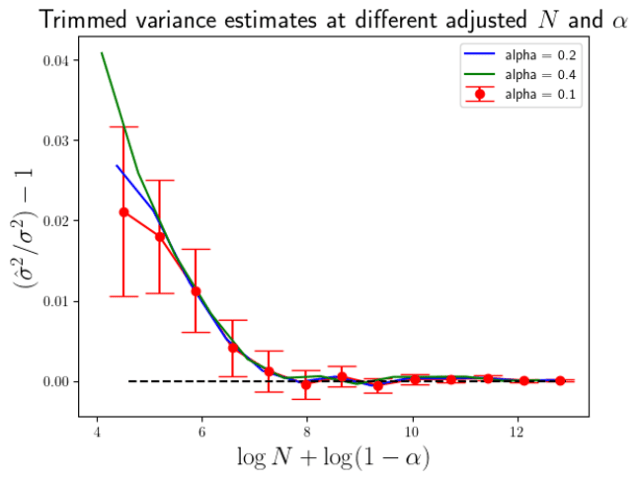
You can see that in Fig.2 all three different 
Getting MAD
So far we have been calculating trimmed variances. However, the idea of using the central portion of a data sample to estimate a population quantity is more widely applicable. One of my favourite and most well known applications of this idea is the median absolute deviation, or MAD for short.
MAD is the median absolute deviation of
The great thing about MAD (when using the median central tendency measure) is that for a large sample of data drawn from a Normal distribution, there is a very simple relationship between the expectation value of MAD and the population standard deviation

Let’s unpack what Eq.7 is telling us. It says that, on average, the MAD calculated from a sample of (Normally distributed) data is a simple constant times the true standard deviation. This means we can invert Eq. 7 to get a extremely simple way of estimating the population standard deviation that is robust to the presence of outliers (provided they make up less than 50% of the sample). That simple way is,

Calculating the MAD is such a common task that once again you will find that most programming languages used for numerical analysis will contain a MAD function either as part of the base distribution, or in a commonly used package. In R we can use the mad function which is part of the base R distribution. In Python we can use scipy.stats.median_abs_deviation. In both cases the use of MAD to estimate the standard deviation is such a common use of MAD that both the R and Python functions have the correction factor of 1.4826 built in. In R, it is included by default, meaning that if you call mad, it will return the Normal adjusted estimate of scipy.stats.median_abs_deviation function we have to explicitly tell it that we want the correction factor applied. We do that by setting the scale argument of the function equal to ‘normal’. The code-snippet below illustrates the scipy.stats.median_abs_deviation function in action.
from scipy.stats import median_abs_deviationmad_sd_estimate = median_abs_deviation(a, scale='normal')
For the simulated data used to produce Fig.1 and Fig.2, I also calculated the MAD based estimate of 


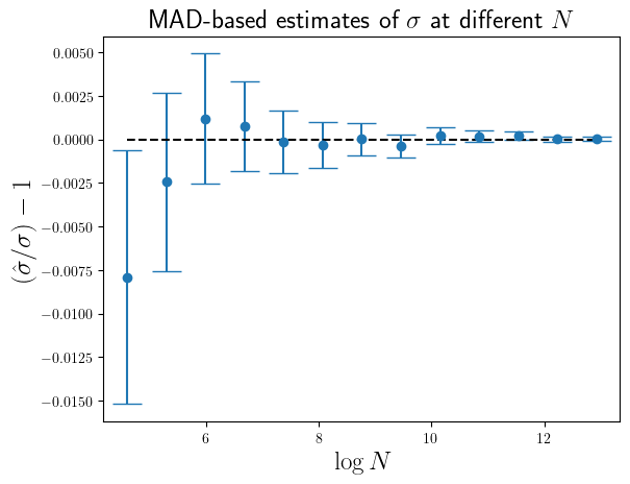
From Fig.3 we can see that the accuarcy of the MAD-based estimate of
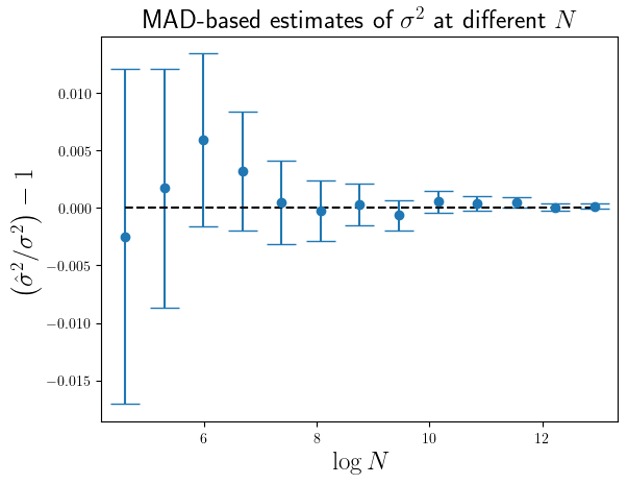
The accuarcy of the MAD-based estimator appears to be, at least for these simulation results, superior to the trimmed-variance estimator, with the errors being around 

Other distributions
So far we have been discussing outlier-contaminated Normal data. But what happens if we are certain our data wasn’t drawn from a Normal distribution with an additional outlier process on top? What happens if we think our data is Gamma-distributed with outliers? We can still apply the same ideas, but it can get trickier and also more computationally intensive. Specifically, we need to distinguish two cases:
- The distribution we assume is still symmetric about its mean – in this case calculating the trimmed variance with an appropriate correction factor, or calculating MAD with an appropriate correction factor is still relatively straight forward. The correction factors may not be expressable in terms of common special functions, or in the worst case you may have to evaluate them numerically, once you have reduced the calculation down to some canonical form.
- The assumed distribution is not symmetric about its mean – in these circumstances it can become a lot trickier. Obviously, now things such as the skewness of the distribution affect the value of MAD or the trimmed-variance value, and so calculation of the correction factors is now affected by the shape of the distribution. This means we typically need to estimate a ‘shape’ parameter of the parametric distribution as well as estimating the ‘scale’ parameter of the distribution, which is the thing we are predominantly interested in. This will mean solving for shape and scale parameters simultaneously, and we are probably going to have to do that root finding numerically, as it is unlikely we can do it analytically. Calculating the appropriate adjustment factors is usually possible in these circumstances, but is typically more computationally intensive and/or we have to introduce additional approximations.
Conclusions
- In many situations we want to estimate the standard deviation of a distribution from a sample of data, but we know there are outliers present in the sample.
- We can’t use our usual estimate of the standard deviation to detect the outliers, because that estimate is affected by the outliers.
- By making an assumption about the parametric form of the distribution whose standard deviation we are trying to estimate, we can estimate the standard deviation using data from any part of the distribution. This means we can use just the middle part of the sample data.
- If we throw away a fraction
- In R and Python there are convenient functions for calculating the trimmed-variance of a sample and also the Normal-consistent MAD-based estimate of the population standard deviation.
- Calculation of trimmed-variance and MAD-based estimates of variance is possible for distributions other than the Normal but will be more computationally intensive, particularly for asymmetric distributions.
© 2026 David Hoyle. All Rights Reserved