

Principal Component Analysis (PCA) is a commonly applied algorithm in statistics and data science. Because it is so easy to understand at a high-level, and because it is so easy to apply, PCA has become ubiquitous. It is often applied without much thought and with the output rarely questioned. Typically, the questions I ask when applying PCA are,
- Do I need to do any transformation of the data before applying PCA?
- How many principal components should I select?
- How do I interpret the loadings (and scores)?
Unfortunately, I have seen a number of talks and presentations recently where PCA has been used and the impact on the analysis of not having thought about these questions was clear. Ok, I’m biased, as the behaviour of PCA, particularly when applied to high-dimensional data, is one of my areas of research. Whilst the research papers on PCA can be very complex, they do however provide some useful insight and guides on how to apply PCA to real data. In this post I’m going to look at those three questions in turn. In the following I’m also going to assume you are already familiar with PCA and that you are aware that the principal components are the eigenvectors of the sample covariance matrix corresponding to the largest eigenvalues. For a good introduction to PCA see the blog post by Laura Hamilton and also the classic book by Jolliffe.
TL;DR – the the short answers to the questions above are, i) Check for outliers and/or heavy tails in your data before applying PCA, ii) use the ‘knee’ in the eigenvalue scree plot to select the number of components, iii) make sure you look at the loadings of the selected principal components and that you can explain any major patterns in those loadings.
1. Transformation of the data
The original derivations of PCA, such as that by Hotelling (1933), are heuristic and make no explicit assumptions other than the requirement that the selected components retain as much of the variance in the original data as possible. The formal derivation of PCA as the maximum likelihood estimate of parameters of a probabilistic model assumes additive Gaussian noise – see for example the paper by Tipping and Bishop. In practice, where the distributions of latent factors and additive noise are still reasonably symmetric and decay sufficiently fast we would expect deviations from perfect Gaussians to have only a minor effect. Despite this I have seen a number of talks with PCA plots similar to that shown on the left below.

I have based this example on a real commercial data set I was shown, but for privacy and confidentiality reasons I have generated a simulated data set that reproduces the issue. The majority of PC1 scores are very squashed into the left hand side of the plot, with a few scores reaching much higher values than the rest. This can been seen more clearly if we look at the estimated density of the 1st PC scores – see the right hand plot above. A heavy tail is clearly present, meaning we are deviating significantly from the assumptions under which the eigenvectors of the sample covariance matrix are the optimal estimators of the signal directions in the raw data.
So an obvious first step would be to take a quick look at the distribution of the raw data that we are trying to decompose using PCA. If that distribution has a heavy tail or significant outliers then there is an argument for applying a transformation (e.g. logarithm) before applying PCA. If we take the log of the example data above then we obtain much more reasonable distributions for the PC scores – see below.

Tip: If you see an elongated distribution of scores along the PCs you have selected, then it may be worth going back and looking at the distribution of the raw data going into the PCA – you should have already looked at the distribution of your raw data anyway as part of EDA best practice.
2. Selection of the number of components
There are two common methods for selecting the number of components that most people will be familiar with or encounter. Those are,
- Select the number of components so that a fixed proportion, e.g. 90%, of the total variance is retained.
- Look at a scree plot of the eigenvalues and locate the ‘elbow’ (or ‘knee’ depending on your interpretation of anatomy).
Of those two methods it is the second that I always prefer. This is because it has a sound theoretical underpinning and is more robust when applied to the kind of high-dimensional data sets that are commonplace nowadays. Let me explain why. The goal of PCA is to select a small number of directions in the data that we believe capture the signal within the data. The first approach to PCA model selection is effectively based upon the assumption that the ‘signal’ contribution to the total variance is considerably greater than the noise contribution to the total variance, and thus by selecting to retain the majority of the total variance in the original data we believe we are effectively selecting components that represent signal.
If our data points are 



Typically, there is no reason to believe that the noise process affects any of the original features/variables more strongly than the others – i.e. it is reasonable to consider the noise process to be isotropic. If not, then the preferred directions are essentially some form of signal and not noise. This means we expect the noise eigenvalues to be approximately the same, and let’s say they have an average value 




and so decreases as the data dimension
In contrast, if the true eigenvalues are split into a small number of ‘signal’ eigenvalues and a much larger number of ‘noise’ eigenvalues and we expect the noise process to be isotropic (i.e. we have a single highly degenerate noise eigenvalue), then the observed (sample) eigenvalues will also consist of a bulk of eigenvalues clustered around a single value and a small number of larger eigenvalues separated from this bulk. In other words we expect to see the distribution of sample covariance eigenvalues look something like the plot on the left below.

The eigenvalues in this example have been obtained from the sample covariance matrix of inter-day returns of closing prices over the 4 year period 2010 to 2013 for S&P500 stocks. We have actually omitted the largest eigenvalue, as this of a different scale and represents a ‘market-mode’ – see the next section.
Note that the bulk of the sample eigenvalues show some dispersion even though we had only one true, highly degenerate, noise eigenvalue. This is due to sampling variation, i.e. the fact that we have only a finite sized sample. If we plot the top 20 eigenvalues from the distribution above, ranked from largest to smallest, we get a scree plot looking like the plot on the right above.
Clearly, the sample eigenvalues corresponding to the bulk are very similar to each other, and so we see only small decreases with increasing rank in the sample eigenvalues in the bulk. In contrast, where there is an atypical jump in eigenvalue as we decrease the rank, this represents the point at which a signal eigenvalue can be detected as being separate from the bulk. This point also represents the ‘knee’ of the scree plot.
Statistical models that produce this kind of scree-plot are called ‘spiked-covariance’ models, so-called because the true population eigenvalue distribution is concentrated (or spiked) around just a small number of values. For these models we consider the data to have been produced by a small number of latent factors with isotropic noise. That is, our data point 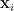

with the vectors 
From the mathematical form of the spiked-covariance models we can work out the expected distribution of sample covariance eigenvalues when our data consists of 
Also on the pragmatic side I have often found that simple ‘knee’ detection algorithms work surprisingly well, particularly for real ‘real-world’ data sets that I encounter as part of my day-to-day work. The simplest of such algorithms involves finding the maximum in the value of a discrete approximation to the second derivative of the ranked eigenvalue plot. That is, we choose

Improved approaches to ‘knee’ detection are based upon discrete approximations of the curvature. The paper by Satopää et al gives a good introduction to such methods. Again, these simple ‘knee’ detection approaches have the advantage that they can be coded and hence included as part of some automated process.
Note that in situations where the signal eigenvalues (those distinct from the bulk) do contribute the majority of the variance in the original data, then selecting the number of PCs on the basis of detecting a ‘knee’ in a scree plot will have the same advantages as selecting on the basis of wanting to retain a certain fixed percentage of the total variance. Consequently, there is very little reason not use the scree plot for selection in all cases.
3. Interpretation of the loadings
I have also found it is not uncommon for PCA to be blindly applied and the scores, i.e. the values of the new, lower-dimensional, features to be plotted, fed into some downstream process without any further curiosity being applied. Where the leading sample eigenvalue is very large – that is on a different scale to the other principal components retained or the bulk of the sample eigenvalues – I always take a look at the loadings. This is the case for the S&P500 data discussed above. The loadings tell us the contribution each of the original variables make to the principal component. The loadings for the 1st principal component of the S&P500 data is shown in the plot below,

Where the 1st sample eigenvalue is very large (compared to the others) it is not uncommon to see a loading pattern like that above – each loading value is of the same sign (and in this case of comparable size). The large 1st eigenvalue tells us that variation along the 1st principal component is the dominant mode of variation present in the original data. The loading pattern tells us that in this mode of variation all the original variables increase together, or decrease together. Such a pattern is often termed a ‘global mode’, i.e. it is a mode of variation that largely has the same effect globally on all the original variables. There are several scenarios and situations were the presence of a global mode can be naturally explained or is to be expected. For example,
- Market modes in stock prices. This is where a rising or falling market causes all stock prices to rise or fall together.
- In gene expression data obtained from model organisms exposed to a large environmental perturbation or insult. Here, for model organisms, e.g. yeast cultures, we can shock the biological system being studied without any ethical concerns, e.g. starve the organism of its primary food/fuel source or other essential nutrients. Consequently we see a system wide response to the starvation.
- Price sensitivities of a collection of products sold by a retailer in a store. Here we expect price elasticities of products will reflect, to a large part, the economic conditions of the local geography. Consequently, a predominant part of the variation in product elasticities will be due to store-to-store variation in economic conditions and may show up as a global mode.
Where we see a global mode in the loadings, we should ask whether we can identify a credible mechanism behind the global mode. If not, then this should make us cautious about the appropriateness of the 1st principal component and hence the complete decomposition.
Finally it is worth mentioning that, if a sparse loading pattern is more naturally expected or convenient then sparse versions of PCA can be used. The lecture notes by Rob Tibshirani provide a good introduction to sparse PCA.

