Using AI for mathematics research is a much less hyped field than GenAI in general.
The pre-print, “The Shape of Math To Come”, from Alex Kontorovich gives an excellent recent, readable, and accessible discussion of the potential for using AI to scale-up and automate formal mathematics research.
Introduction
Like the rest of the universe I’ve been drawn into experimenting with GenAI for general productivity tasks. However, one of my other interests is how GenAI gets used in scientific discovery. Even more interesting is how GenAI can be used in mathematical discovery. If you want to know where the combination of mathematics and AI is going or could go, then I would strongly recommend reading this arXiv pre-print from Alex Kontorovich, titled “The Shape of Math To Come”. The pre-print was uploaded to the archive in October of this year. With some free evenings last week, I finally got round to finish reading and digesting it.
GenAI for rigorous mathematics? Really?
It’s important to point out that I’m not talking about the mathematics behind GenAI, but about how GenAI is used or could be used as a tool to support the formal development of rigorous mathematical proofs, derivations and statements. Because of that rigour, there is actually less hype (compared to mainstream applications of GenAI) around the use of AI in this way. In the pre-print Kontorovich outlines a credible and believable road ahead for using GenAI in formal mathematics. For me the roadmap is credible because of i)Kontorovich’s credentials as Distinguished Professor of mathematics at Rutger’s University, ii) the significant progress that has been made in this area over the last couple of years, particularly the AlphaProof system from DeepMind, iii) and the existence of powerful automated theorem provers such as Lean.
The pre-print is very readable and even if you don’t have a formal mathematical background but have, say an undergraduate science or engineering degree, you will be able to follow the majority of the discussion – there is only one place where specialized knowledge of analysis is used and even then it is not essential for following Kontorovich’s argument.
The main potential sticking point that Kontorovich highlights in using AI to do maths is the tension between the stochastic nature of Large Language Models (LLMs) and the deterministic nature of mathematical proof. Kontorovich’s argument is that the use of automated theorem checkers such as Lean, in combination with a large and increasing library (MathLib) that formally encodes our current rigorous mathematical knowledge base, will provide a checking mechanism to mitigate the stochastic nature of LLM outputs. In this scenario, human mathematicians are elevated to the role of orchestrating and guiding the LLMs in their attempts to construct new proofs and derivations (using Lean and aided by the knowledge base encoded in MathLib). Whether human mathematicians choose to adopt this approach will depend on how fruitful and easy to use the new GenAI-based mathematics tools are. By analogy with the take-up of the LaTeX typesetting language in the early 1990s, Kontorovich says that this will be when “the ratio of time required to discover and formalize a mathematical result (from initial idea through verified formal proof) to the time required to discover and write up the same result in natural language mathematics” falls below one. When this happens there will also be accelerated ‘network’ effects – increased number of verified proofs encoded into MathLib will increase the ability of computer + GenAI assisted workflows to construct further verified proofs.
Less formal mathematics research
What interests me as a Data Scientist is, if such approaches are successful in advancing how mathematicians do formal mathematics, how much of those approaches can be adopted or modified to advance how non-mathematicians do non-formal mathematics. I’m not talking about the “closed-loop” GenAI-based “robot scientist” approaches that are being discussed in drug-discovery and materials development fields. I’m talking about the iterative, exploratory process of developing a new model training algorithm for a new type of data, or new application domain, or new type of problem. Data Science is typically about approximation. Yes, there is formal derivation in places, and rigorous proofs in others, but there is also a lot of heuristics. Those heuristics can be expressed mathematically, but they are still heuristics. This is not a criticism of using such heuristics – sometimes they are used out of ignorance that better approaches exist, but often they are used out of necessity arising from constraints imposed by the scale of the problem or runtime and storage constraints. What I’m driving at is that the Data Science development process is a messy workflow, with some steps being highly mathematical and imposing a high degree of rigour, some less so. Having access to proven tools that accelerate the exploration of the mathematical steps of that workflow can obviously accelerate the overall Data Science development process. At the moment, switching between mathematical and non-mathematical steps introduces context-switching and hence friction, so my tool use for the mathematical steps is limited. I might use Mathematica for an occasional tedious expansion and where tracking and collating expansion terms is error-prone. For my day-to-day work my mathematical steps will be limited to, say, 40 pages of A4, and are more typically between 5 – 15 pages of A4, and occasionally 1-2 pages. At such scales, I can just stick to pen-and-paper. If however, mathematical support tools developed from doing formal mathematics research became more seamlessly integrated into the Data Science development process, I would change my way of working. However, there is another problem. And that is the messy nature of the Data Science development process I outlined. Not all the steps in the process are rigorous. That means the Data Science development workflow doesn’t have access to the self-correcting process that formal mathematics does. In Alex Kontorovich’s paper he makes an optimistic case for how the use of formal theorem checkers, in combination with GenAI, can genuinely advance formal mathematics. I think of this as akin to how physics-based engines are used to provide rigorous environments for reinforcement-learning. The messy Data Science workflow typically has no such luxury. Yes, sometimes we have access to the end-point ground-truth, or we can simulate such truths under specified assumptions. More often than not, our check on the validity of a specific Data Science development workflow is an ad-hoc combination of data-driven checks, commercial vertical domain expertise, technical vertical expertise, and hard-won experience of ‘what works’. That needs to get better and faster. I would love for some of the tools and processes outlined by Kontorovich to be adapted to less formal but still mathematically-intensive fields such as the algorithm development side of Data Science. Will it happen? I don’t know. Can it be done? I don’t know, as yet.
TL;DR: Having a high-level understanding of the mathematics of transformers is important for any Data Scientist. The two sources I recommend below are excellent short introductions to the maths of transformers and modern language models.
A colleague asked me, about two months back, if I could recommend any articles on the mathematics of Large Language Models (LLMs). They then clarified that they meant transformers, as they were primarily interested in the algorithms on which LLM apps are based. Yes, they’d skim read the original “Attention Is All You Need” paper from Vaswani et al, but they done so just after the paper came out in 2017. They were looking to get back up to date with LLMs and even revisit the original Vaswani paper. Firstly, they wanted an accessible explanation which they could use to construct a high-level mental model of how transformers worked, the idea being that the high-level mental model would serve as a construct on which to hang and compartmentalize the many new concepts and advances that had happened since the Vaswani paper. Secondly, my colleague is very mathematically able, so they were looking for mathematical detail, but the right mathematical detail, and in a relatively short read.
I’ve listed below the recommendations I gave to my colleague because I think they are good recommendations (and I explain why below as well). I also believe it is important for all Data Scientists to have at least a high-level understanding of how transformers, and the LLMs which are built on them, work – again I explain why, below.
The recommendations
What I recommended was one paper and one book. The article is free to access, and the book has a “set your own price” option for access to the electronic version of the book.
The article is, “An Introduction to Transformers” by Richard Turner from the Dept. of Engineering at the University of Cambridge and Microsoft Research in Cambridge (UK). This arXiv paper can be found here. The paper focuses on how transformers work but not on training them. That way the reader focuses on the structure of the transformers without getting lost in the details of the arcane and dark art of training transformers. This is why I like this paper. It gives you an overview of what transformers are and how they work without getting into the necessary but separate nitty-gritty of how you get them to work. To read the paper does require some prior knowledge of mathematics but the level is not that high – see the last line of the abstract of the paper. The whole paper is only six pages long, making it a very succinct explanation of transformer maths that you can consume in one sitting.
The book is “The Hundred-Page Language Models Book” by Andriy Burkov. This is the latest in the series of books from Burkov, that include “The Hundred-Page Machine Learning Book” and “Machine Learning Engineering”. I have a copy of the hundred-page machine learning book and I think it is ok, but I prefer the LLMs book. I think part of the reason for this is that, like everybody else I have been only been using and playing with LLMs for the last three years or so, whilst I have been doing Data Science for a lot longer – I have been doing some form of mathematical or statistical modelling for over 30years – and so I didn’t really learn anything new from the machine learning book. In contrast, I learnt a lot from the book on LLMs. The whole book works through simple examples, both in code (Python) and in terms of the maths. I semi-skim read the book in two sittings. The code examples I skipped, not because they were simplistic but because I wanted to digest the theory and algorithm explanations end-to-end first and then return to trying the code examples at a later date. Overall, the book is packed with useful nuggets. It is a longer read than the Turner paper, but can still easily be consumed in a day if you skip bits. The book assumes less prior mathematical knowledge than the Turner paper and explains the new bits of maths it introduces, but given the whirlwind nature of a 100-page introduction to LLMs I would still recommend you have some basic familiarity with linear algebra, statistics & probability, and machine learning concepts.
Why learn the mathematics of transformers?
Having to think about which short articles I would recommend on the maths of transformers and LLMs made me think more broadly about whether there is any benefit from having a high-level understanding of transformer maths. My colleague was approaching it out of curiosity, and I knew that. They simply wanted to learn, not because they had to, nor because they thought that understanding the mathematical basis of transformers was the way to approach using LLMs as a tool.
However, given the exorbitant financial cost of building foundation models and the need to master a vast amount of engineering detail, most people won’t be building their own foundation models. Instead they will be using 3rd party models simply as a tool and focusing on developing skills and familiarity in prompting them. So, are there any benefits then to understanding the maths behind LLMs? In other words, could I honestly recommend the two sources listed above to anybody else other than my colleague who was interested mainly out of curiousity?
The benefits of learning the maths of transformers and the risks of not doing so
The answer to the question above, in my opinion, is yes. But you probably could have guessed that from the fact I’ve written this post. So, what do I think are the benefits to a Data Scientist in having a high-level understanding of the mathematics of transformers? And equally important, what are the downsides and risks of not having that high-level understanding?
Having even a high-level understanding of the maths behind transformers de-mystifies LLMs since it forces you to focus on what is inside LLMs. Without this understanding you risk putting an unnecessary veneer of complexity or mysticism on top of LLMs, a veneer that prevents you using LLMs effectively.
You will understand why LLMs hallucinate. You will understand that LLMs build a model of the high-dimensional conditional probability distribution of the next token given the preceding context. And that distribution can have a large dispersion if the the training data is limited in the high-dimensional region that corresponds to the current context. That large dispersion results in the sampled next token having a high probability of being inappropriate. If you understand what LLMs are modelling and how they model it, hallucinations will not be a surprise to you (they may still be annoying) and you will understand strategies to mitigate them. If you don’t understand how LLMs are modelling the conditional probability of the next token, you will always be surprised, annoyed, and impacted by LLM hallucinations.
It helps you understand where LLMs excel and where they don’t because you have a grounded understanding of their strengths and weaknesses. This makes it easier to identify potential applications of LLMs. The downside? Not having a fundamental understanding of the strengths and weaknesses of the algorithms behind LLMs risks you building LLM-based applications that were doomed to failure from the start because they have been mis-matched to the capabilities of LLMs.
By having a high-level mental model of transformers on which to hang later advances in LLMs, you can more easily identify what is important and relevant (or not) in any new advance. The downside to not having this well-founded mental-model is that you get blown about by the winds of over-hyped LLM announcements from companies stating that their new tool or app is a “paradigm shift”, and consequently you waste time getting into the detail of what are trivial or inconsequential improvements.
What to do?
What should you do if you are a Data Scientist and I have managed to convince you that having a high-level understanding of the mathematics of transformers is important? Simple, access the two sources I’ve recommended above. Happy reading.
AWS SageMaker provides a number of standard Machine Learning algorithms in containerized form, so you can pull those algorithms down onto a large EC2 instance and just run, with minimal effort.
AWS SageMaker also provides a hyperparameter optimization functionality that pretty much runs ‘out-of-the-box’ with the algorithms provided.
You can run your own algorithms within SageMaker if you containerize your algorithm code.
I wanted to find out if it was possible to easily combine the ‘run-your-own-containerized-algorithm’ functionality with the ‘out-the-box’ hyperparameter optimization functionality in SageMaker. It is. It was a straight-forward, but slightly lengthy process.
Introduction
<DISCLAIMER> This is a blog-post I started back in Autumn/Winter 2019. I knew it would be a fairly length post but one I was keen to write. But then, well, a pandemic got in the way and its taken a while to get back to writing blog posts. I still believe there are some useful learnings here – I hope you do too </DISCLAIMER>.
Back in 2019 I was using SageMaker a lot, including running an AWS Machine Learning Immersion Day at Infinity Works. One of the things I like about SageMaker is how the resources used to do any heavy lifting in training a model are separated from the resources supporting the Jupyter notebook. The SageMaker service provides several standard Machine Learning algorithms (e.g. Random Forests, XGBoost) in containers. This means it is possible to explore a dataset and develop an modelling approach in a Jupyter notebook that runs on one EC2 instance, and then when we want to scale-up the training process to the full dataset we can pull down the relevant container from ECR and run the training process on a separate much larger instance. Provisioning of heavier infrastructure needed for training on the full large dataset is only done when it is needed and you only pay for what you use of those larger EC2 instances. A Data Scientist like me doesn’t have to worry about the provisioning of the larger EC2 instance, it is handled by through simple configuration options when configuring the training job. It is also possible to configure a hyper-parameter optimization job in a similar way, so that multiple training jobs (with different hyper-parameter values) can be easily run, potentially in parallel, on large EC2 instances just by adjusting a few lines of json config.
So far, so good. As a Data Scientist the pain of getting access to or configuring compute resource has been removed and training on really large datasets is almost as easy as exploring a smaller dataset in a Jupyter notebook running on my local machine. But are we restricted to only using the algorithms that AWS has containerized? This is where it get more interesting and fun. You can use any algorithm that is available in a container in ECS. That means you can develop/code up your own algorithm/training process, containerize it, and then run that algorithm using multiple large EC2 instances with minimal config.
AWS have an example of how to containerize your own algorithm and deploy it to an endpoint. The git repo is here. The AWS team use the example of a scikit-learn decision tree trained on the Iris dataset (I know, why do examples not use something more original than the Iris dataset).
What I wanted to explore was,
How easy was it to actually containerize my own algorithm for use in SageMaker,
How easy was it to combine my containerized algorithm with the easy to configure hyperparameter optimization capability already present in SageMaker.
The rest of this post is about what I learnt in exploring those two questions, in particular the second of those. The first question is essentially already answered by the original AWS repo. What I wanted to learn was could I easily use my own algorithm with the out-the-box hyperparameter optimization functionality that SageMaker provided, or was the easy-to-use hyperparameter optimization functionality essentially restricted to the in-built SageMaker algorithms? What I’ll cover is,
The choice of algorithm we’re going to containerize
The basics of building the Docker container
Pushing the container to the AWS container registry
Using the containerized algorithm within a SageMaker notebook
Running hyperparameter optimization jobs using the containerized algorithm.
If you want to follow the technical details, I would suggest that you first become familiar with the basics of AWS SageMaker – tutorial here. You may also want to look at the basics of hyperparameter tuning for one of the standard machine learning algorithms within SageMaker, as I’ll be assuming some of this background knowledge is known to you or at least you can pick it up quickly – to fully explain all the SageMaker background material would make this an even longer blog. You can find explanations of how to configure and run a SageMaker hyperparameter tuning job here and here.
Now, let’s start with the first of our questions.
Algorithm choice
I wanted to use an algorithm that wasn’t already available within SageMaker, otherwise what would be the point of going through this exercise? I have been doing some work recently on Gaussian Processes (GPs), in particular with kernel functions that are composite functions.
I won’t explicitly cover the basics of GPs here – the blog post is long enough already. Instead I will point you towards the excellent book by Carl Rasmussen and Chris Williams and this tutorial from Neil Lawrence. However, I will say briefly what my interest in GPs is. Gaussian Processes have an interesting connection with large (wide) Neural Networks. This connection was discovered by Chris Williams and Radford Neal. I wrote some GP code, on the basis of the Williams’ paper, that made it into commercial software (my first ever example) back in 1999 (yes – I am that old, and have been working in Machine Learning that long). More recently, the connection has been extended to link Deep Learning Neural Networks and Gaussian Processes (see for example, here and here). Cho & Saul did some nice early work in this area, using dot-product kernels that are composite functions. It is the dot-product kernels derived by Cho & Saul that I’ll use here for my example algorithm, as the kernels are of relatively simple form, and yet are specified in terms of a few simple parameters that we can regard as hyper-parameters. For the purposes of this blog on AWS SageMaker it is not important to know what the Cho & Saul kernels might represent, merely how they are defined mathematically. So let’s start there,
For this illustration we are focusing on datapoints on the the surface of the unit hypersphere, i.e with . We then consider a set of kernels, , defined via,
The dot-product kernels are defined iteratively,
The base kernels are constructed from,
with,
Choosing a particular kernel then boils down to making a choice for q and l. Once we have made choice of kernel, we can train our model. For simplicity, I have defined the model training here to be simply the process of constructing the Gram matrix from the training data, i.e. the process of calculating the matrix elements,
Here, σ2 is the variance of the additive Gaussian noise that we consider present in the response variable, and , are the feature vectors for the N datapoints in the training set. Along with the training feature vectors we also have the response variable values, .
Whilst it may not match the more traditional concept of model training – there is no iterative process to minimize some cost function – I am using the training data to construct a mathematical object required for calculating the expectation of the response variable conditional on the input features. Within a Gaussian Process it is considered usual to optimize any parameters of the covariance kernel as part of the model training. In this case, for simplicity, and for purposes of illustrating the hyperparameter tuning capabilities of SageMaker, I wanted to consider the kernel parameters q,l and σ2 as hyperparameters, essentially leaving no remaining kernel parameters to be optimized during the model training.
Once we have the matrix defined, we can calculate a prediction for the response variable at a new feature vector via the formula,
where is the vector of response values in the training set, and the vector , with the element given by,
Now we have given the mathematical definition of our algorithm, we need to focus on code. Following the example in the original AWS repo we need python code that,
Defines a class for a trained GP model. I have called my class, unsurprisingly, trainedGPModel . Instantiating an instance of this class by passing the training data to the class constructor method, runs the Gram matrix calculation process mentioned earlier. Within my trainedGPModel class I also have a method predict(xstar) that returns the predicted expectation of the response variable given an input datapoint xstar. The code for the trainedGPModel class implements the linear algebra formulae given above and so is straight-forward.
We also need code that runs the training process. This code is held in a file called train. I made minimal modifications to the train module in the original AWS repo. The main change I made was including code to make predictions on a validation dataset, and from that calculating the Root-Mean-Squared-Error (RMSE) on the validation dataset. The validation RMSE is the metric I will use for hyperparameter tuning and so I have to write the validation RMSE value to stdout so that it can get picked up by the SageMaker hyperparameter tuning process. I had to write the RMSE value with a string prefix and delimiter, e.g.
with a corresponding matching regex in the configuration of the hyperparameter tuning job – see later section on running the containerized algorithm in a SageMaker notebook. It wasn’t obvious that I needed to write the validation metric in this way, and it took a bit of googling to work out. Most SageMaker links on hyperparameter tuning point to this page , but the detail on how the metric is passed between your algorithm code and the SageMaker hyperparameter optimization code is actually explained in this SageMaker documentation page.
Docker basics
Now let’s talk about putting our code in a container. We need to construct a Docker compose file. For a refresher on Docker I found this tutorial by Márk Takács to be really helpful. I actually use a Windows machine for my work, so I’m running Docker Desktop. However, I also use WSL (Windows Subsystem for Linux) for when I want a linux like environment. Although you can install a Docker client under WSL, you still have to make use of the native Docker daemon of Docker Desktop. I found this guide from Nick Janetakis on getting the WSL Docker client working with Docker Desktop invaluable, particularly the configuring of where WSL mounts the Windows file system (by editing the /etc/wsl.config file) so that I can then easily mount any sub-directory of my Windows file system to any point I choose in the container image when testing the Docker file locally.
I won’t go through the aspects of testing the container locally – you can read the original AWS repo to see that. Instead we’ll just go through the Docker file for building the final SageMaker container. The Docker file is fairly simple and other that changing it to use a python3 runtime (see lines 9&10) we have not changed anything else in the Docker file in the original AWS repo. Line 36 of the Docker file is where we copy across our algorithm code into pre-specified directory in the image that SageMaker will look for when running the containerized algorithm.
# Build an image that can do training and inference in SageMaker
# This is a Python 3 image that uses the nginx, gunicorn, flask stack
# for serving inferences in a stable way.
FROM ubuntu:18.04
RUN apt-get -y update && apt-get install -y --no-install-recommends \
wget \
python3 \
python3-pip \
nginx \
ca-certificates \
&& rm -rf /var/lib/apt/lists/*
# Here we get all python packages.
# There's substantial overlap between scipy and numpy that we eliminate by
# linking them together. Likewise, pip leaves the install caches populated which uses
# a significant amount of space. These optimizations save a fair amount of space in the
# image, which reduces start up time.
RUN pip3 install numpy scipy scikit-learn pandas flask gevent gunicorn &amp;&amp; \
(cd /usr/local/lib/python3.6/dist-packages/scipy/.libs; rm *; ln ../../numpy/.libs/* .) && \
rm -rf /root/.cache
RUN pip3 install setuptools
# Set some environment variables. PYTHONUNBUFFERED keeps Python from buffering our standard
# output stream, which means that logs can be delivered to the user quickly. PYTHONDONTWRITEBYTECODE
# keeps Python from writing the .pyc files which are unnecessary in this case. We also update
# PATH so that the train and serve programs are found when the container is invoked.
ENV PYTHONUNBUFFERED=TRUE
ENV PYTHONDONTWRITEBYTECODE=TRUE
ENV PATH="/opt/program:${PATH}"
# Set up the program in the image
COPY gaussian_processes /opt/program
WORKDIR /opt/program
Pushing the container to AWS
We can now push our Docker container to the AWS ECR (Elastic Container Registry). This is simple using the AWS CLI (command line interface) and the build_and_push.sh shell script provided in the original AWS repo. Within the shell script we have just modified on lines 16 and 17 the name of the top-level directory in which our training and prediction code resides,
image=$1
if [ "$image" == "" ]
then
echo "Usage: $0 "
exit 1
fi
chmod +x gaussian_processes/train
chmod +x gaussian_processes/serve
Then we just run shell script, passing the name of the container we have just built as a command line argument,
./build_and_push.sh gpsagemaker
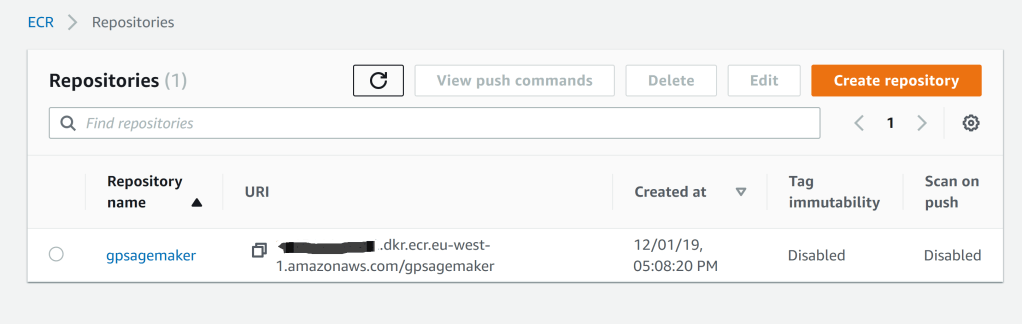
After running the shell script we can see the container present in the AWS ECR,
Screenshot of our Gaussian Process SageMaker Docker container in AWS Elastic Container Registry (ECR) – ready to use within a SageMaker notebook.
Using the containerized algorithm in SageMaker
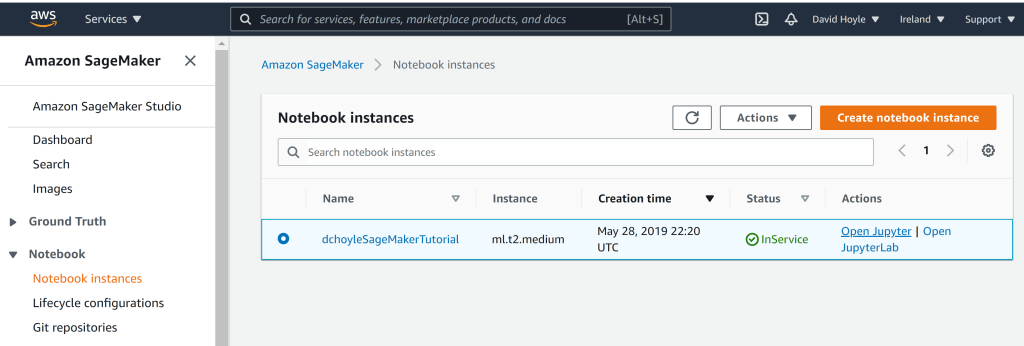
Now we have the container, that has our GP code, in AWS ECR we can use it within a SageMaker notebook. Let’s do so. For this I’m just going to adapt the notebook within the original AWS repo. I go to the Sagemaker under ‘ML’ in the list of AWS services and from there I can start/create my SageMaker notebook instance. Once the notebook instance is ready I can open up a Jupyter notebook as usual,
The first main difference is that we’ll create some simple small-scale simulated training and validation data. Our goal here is to test how easy it is to containerize and use our own algorithm, not build a perfect model. Our generative model is a simple one – a linear model, dependent on just two features (with coefficients that we have chosen as 1.5 and 5.2 respectively). We use this simple model to create the response variable values and then add some Gaussian random noise (of unit variance).
We also set values for the hyperparameters, which are static since we are just running a single training job and not doing any hyperparameter optimization yet.
We can then run a training job using our containerized Gaussian Process code, just as we would any other algorithm available in SageMaker. We can see the training job running in the AWS Management console – click under “Training jobs” on the left hand side of the console. We can see the current training job ‘in progress’ and also an earlier completed training job that I ran.
Screenshot of a single SageMaker training job running using our GP algorithm code.
Running a hyperparameter tuning job
So that appears to run ok. So now we have our algorithm running in SageMaker ok, we can now just configure the SageMaker hyperparameter optimization wrapper and run one of the out-of-box SageMaker hyperparameter optimization algorithms over what we have specified as hyperparameter in our Gaussian Process code. The config for the hyperparameter tuning job is below – we have largely just modified slightly the examples in the original AWS repo and also followed the guidance. You can see that we have specified the RMSE metric on the validation set as the metric to optimize with respect to the hyperparameters. For illustration purposes we have specified that we want to optimize only over the q and l hyperparameters. The σ2 hyperparameter we have kept static at σ2=0.1. You can also see that we have specified to run 10 training jobs in total, i.e. we will evaluate the validation metric at 10 different combinations of the two hyperparameters, but we only run 3 training jobs in parallel at any one time.
# Define HyperParameterTuningJob
# We will only tune the learning rate by maximizing the AUC value of the
# validation set. The hyperparameter search is a random one, using a sample of
# 10 training jobs - better methods for searching the hyperparameter space are
# available, but for simplicty and demonstration purposes we will use the
# random search method. Run a max of 3 training jobs in parallel
job_name = "gpsmbyo-hp-" + strftime("%Y-%m-%d-%H-%M-%S", gmtime())
response = sm.create_hyper_parameter_tuning_job(
HyperParameterTuningJobName=job_name,
HyperParameterTuningJobConfig={
'Strategy': 'Random',
'HyperParameterTuningJobObjective': {
'Type': 'Minimize',
'MetricName': 'validation:RMSE'
},
'ResourceLimits': {
'MaxNumberOfTrainingJobs': 10,
'MaxParallelTrainingJobs': 3
},
'ParameterRanges': {
'IntegerParameterRanges': [
{
"Name": "q",
"MaxValue": "4",
"MinValue": "0",
"ScalingType": "Auto"
},
{
"Name": "l",
"MaxValue": "4",
"MinValue": "1",
"ScalingType": "Auto"
}
]}
},
TrainingJobDefinition={
'StaticHyperParameters': {
"noise":"0.1"
},
'AlgorithmSpecification': {
'TrainingImage': image,
'TrainingInputMode': "File",
'MetricDefinitions':[{"Name":"validation:RMSE",
"Regex":"validation:RMSE=(.*?);"
}]
}
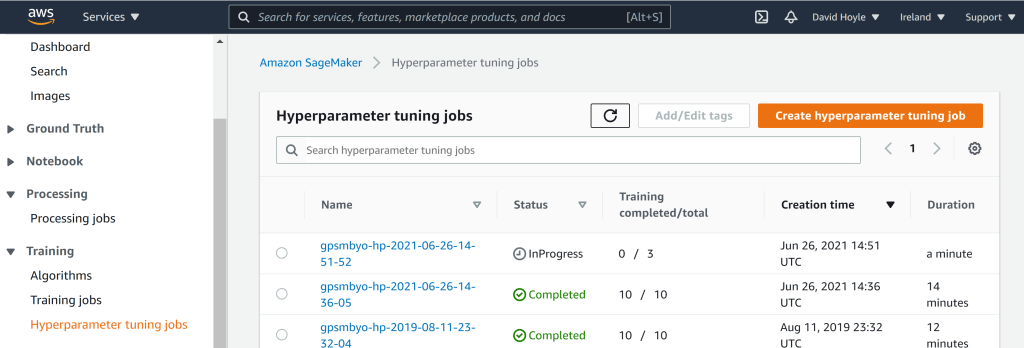
If we then look at our AWS console (screenshot below) we can see the hyperparameter tuning job running, along with previous completed tuning jobs.
Screen shot of AWS console showing current and previous hyperparameter tuning jobs.
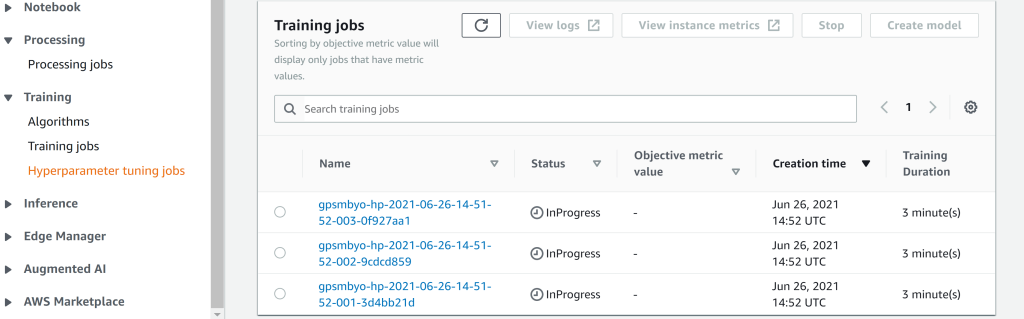
We can also see the individual training jobs, corresponding to that tuning job, running (screenshot below). Remember that the hyperparameter tuning job is just a series of individual evaluations of the validation metrics, run at combinations of (q,l) specified the tuning algorithm. From the screenshot we can see that there are 3 training jobs running, in accordance with what we specified in the tuning job config.
Screenshot of the 3 training jobs running as part of the hyperparameter tuning job.
Once the tuning job has completed, we can retrieve the validation metric values for the 10 different hyperparameter combinations that were tried, to see which combination of q and l gave the smallest RMSE on the validation set.
Summary
The two questions I was trying to address were,
How difficult is it to create your own algorithm to use in SageMaker?
How easy is it to use the hyperparameter optimization algorithms available in SageMaker with your new algorithm?
The answer to both questions is, “it is a relatively easy but lengthy process”. That it is a lengthy process is understandable – SageMaker gives you a functionality to apply out-the-box hyperparameter tuning on an algorithm/code that it knows nothing about until runtime. Therefore there has to be a lot of standardized syntax in specifying how that algorithm is structured and called as a piece of code. Fortunately, all the details of how to structure your algorithm and create the Docker container are in the excellent example given in the AWS repo and the documentation. The only complaint I would have is that it would be good for the repo to have an example showing how your own algorithm can utilize the hyperparameter optimization functionality of SageMaker – hence this blog. Working out the few remaining steps to get the hyperparameter optimization working with my Gaussian Process code was not very difficult, but not easy either.
The example algorithm I have chosen is very simplistic – the training process literally only involves the calculation and inversion of a matrix. A full training process could involve optimization of, say, the log-likelihood with respect to the parameters of the kernel function, but explaining the extra details would make this blog even long. Secondly, we only needed a simple/minimal training process to address the two questions above. Likewise, we have not illustrated our new trained algorithm being used to serve predictions – this is very well illustrated in the original repo and I would not be adding any new with my Gaussian Process example.
I have been doing some work recently on Restricted Boltzmann Machines (RBMs). Specifically, I have been looking at the evaluation of the log of the partition function.
RBMs consist of a layer of visible nodes and a layer of hidden nodes, with the number of hidden nodes typically being less than the number of visible nodes. Where both visible and hidden nodes have binary states we can think of the RBM as performing a discrete-to-discrete dimensionality reduction. Stacked RBMs provided some of the earliest examples of deep learning neural networks – see for example the work of Hinton and Salakhutdinov.
The partition function Z is the normalizing constant for the joint distribution over the states of the visible and hidden nodes, and is often used for model selection, i.e. when we want to control or select the right level of complexity in the RBM. I wanted to test out some of the ideas behind the message passing algorithm of Huang and Toyoizumi (arxiv version here). Huang and Toyoizumi use a Bethe approximation to develop a mean-field approximation for log Z. As usual, the self-consistent mean-field equations lead to a set of coupled equations for the expected magnetization, which are solved iteratively leading to the passing of information on local field strengths between nodes – the so-called message passing. To test the Huang and Toyoizumi algorithm I need to know the true value of log Z.
A standard, non mean-field, method for evaluation of the log-partition function is the Annealed Importance Sampling (AIS) algorithm of Salakhutdinov and Murray, who base their derivation on the generic AIS work of Neal (arxiv version). The AIS algorithm is an Monte Carlo based approach and samples from a series of RBMs that go from being completely decoupled (no visible to hidden node interactions) to the fully coupled RBM of interest.
I have pushed my implementations of the Huang and Toyoizumi message passing algorithm and the Salakhutdinov and Murray AIS algorithm to github. However, there is still the question of how do I test the implementations given that there is no simple closed form analytical expressions for log Z when we have visible to hidden node coupling? Fortunately, as the RBMs are of finite size, then for sufficiently small hidden and visible layers we can evaluate logZ ‘exactly’ via complete enumeration of all the states of the visible and hidden layers. I say ‘exactly’ as some numerical approximation can be required when combining terms in the partition function whose energies are on very different scales. I have also included in the github repository code to do the ‘exact’ evaluation.
This week saw interesting news and career guide articles in Nature highlighting Chinese government plans for its AI industry. The goal of the Chinese government is to become a world leader in AI by 2030. China forecasts that the value of its core AI industries will be US$157.7Billion in 2030 (based on exchange rate at 2018/01/19). How realistic that goal is will obviously depend upon what momentum there already is within China’s AI sector, but even so I was still struck and impressed by the ambition of the goal – 2030 is only 12 years away, which is not long in research and innovation terms. The Nature articles are worth a read (and are not behind a paywall).
What will be the effect of China’s investment in AI? Attempting to make technology based predictions about the future can be ill-advised, but I will speculate anyway, as the articles, for me, prompted three immediate questions:
How likely is China to be successful in achieving its goal?
What sectors will it achieve most influence in?
What are competitor countries doing?
How successful will China be?
Whatever your opinions on the current hype surrounding AI, Machine Learning, and Data Science, there tends to a consensus that Machine Learning will emerge from its current hype-cycle with some genuine gains and progress. This time it is different. The fact that serious investment in AI is being made not just by corporations but by governments (including the UK) could be taken as an indicator that we are looking beyond the hype. Data volumes, compute power, and credible business models are all present simultaneously in this current AI/Machine Learning hype-cycle, in ways that they weren’t in the 1980s neural network boom-and-bust and other AI Winters. Machine Learning and Data Science is becoming genuinely commoditized. Consequently, the goal China has set itself is about building capacity, i.e. about the transfer of knowledge from a smaller innovation ecosystem (such as the academic community and a handful of large corporate labs) to produce a larger but highly-skilled bulk of practitioners. A capacity building exercise such as this should be a known quantity and so investments will scale – i.e. you will see proportional returns on those investments. The Nature news article does comment that China may face some challenges in strengthening the initial research base in AI, but this may be helped by the presence of large corporate players such as Microsoft and Google, who have established AI research labs within the country.
What sectors will be influenced most?
One prominent area for applications of AI and Machine Learning is commerce, and China provides a large potential market place. However, access to that market can be difficult for Western companies and so Chinese data science solution providers may face limited external competition on their home soil. Equally, Chinese firms wishing to compete in Western markets, using expertise of the AI-commerce interface gained from their home market, may face tough challenges from the mature and experienced incumbents present in those Western markets. Secondly, it may depend precisely on which organizations in China develop the beneficial experience in the sector. The large US corporates (Microsoft, Google) that have a presence in China are already main players in AI and commerce in the West, and so may not see extra dividends beyond the obvious ones of access to the Chinese market and access to emerging Chinese talent. Overall, it feels that whilst China’s investment in this sector will undoubtedly be a success, and Chinese commerce firms will be a success, China’s AI investment may not significantly change the direction the global commerce sector would have taken anyway with regard to its use and adoption of AI.
What are China’s competitors investing in this area?
I will restrict my comments to the UK, which, being my home country, I am more familiar with. Like China, the UK has picked out AI, Robotics, and a Data Driven Economy as areas that will help enable a productive economy. Specifically, the UK Industrial Strategy announced last year identifies AI for one of its first ‘Sector Deals’ and also as one of four Grand Challenges. The benefits of AI is even called out in other Sector Deals, for example in the Sector Deal for the Life Sciences. This is on top of existing UK investment in Data Science, such as the Alan Turing Institute (ATI) and last year’s announcement by the ATI that it is adding four additional universities as partners. In addition we have capacity-building calls from research councils, such as the EPSRC call for proposals for Centres for Doctoral Training (CDTs). From my quick reading, 4 of the 30 priority areas that the EPSRC has highlighted for CDTs make explicit reference to AI, Data Science, or Autonomous Systems. The number of priority areas that will have some implicit dependence on AI or Data Science will be greater. Overall the scale of the UK investment is, naturally, unlikely to match that of China – the original Nature report on the Chinese plans says that no mention of level of funding is made. However, the likely scale of the Chinese governmental investment in AI will ultimately give that country an edge, or at least a higher probability of success. Does that mean the UK needs to re-think and up its investment?
Notes:
An English-language government summary of the plan, published on the 20th July 2017, can be found here.




 with
with  . We then consider a set of kernels,
. We then consider a set of kernels, 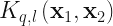 , defined via,
, defined via, 
 are defined iteratively,
are defined iteratively,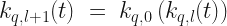
 are constructed from,
are constructed from,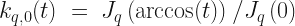


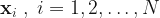 , are the feature vectors for the N datapoints in the training set. Along with the training feature vectors we also have the response variable values,
, are the feature vectors for the N datapoints in the training set. Along with the training feature vectors we also have the response variable values, 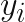 .
.  defined, we can calculate a prediction for the response variable at a new feature vector
defined, we can calculate a prediction for the response variable at a new feature vector 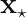 via the formula,
via the formula,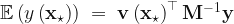
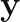 is the vector of response values in the training set, and the vector
is the vector of response values in the training set, and the vector 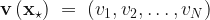 , with the element
, with the element  given by,
given by,