
This week saw interesting news and career guide articles in Nature highlighting Chinese government plans for its AI industry. The goal of the Chinese government is to become a world leader in AI by 2030. China forecasts that the value of its core AI industries will be US$157.7Billion in 2030 (based on exchange rate at 2018/01/19). How realistic that goal is will obviously depend upon what momentum there already is within China’s AI sector, but even so I was still struck and impressed by the ambition of the goal – 2030 is only 12 years away, which is not long in research and innovation terms. The Nature articles are worth a read (and are not behind a paywall).

What will be the effect of China’s investment in AI? Attempting to make technology based predictions about the future can be ill-advised, but I will speculate anyway, as the articles, for me, prompted three immediate questions:
- How likely is China to be successful in achieving its goal?
- What sectors will it achieve most influence in?
- What are competitor countries doing?
How successful will China be?
Whatever your opinions on the current hype surrounding AI, Machine Learning, and Data Science, there tends to a consensus that Machine Learning will emerge from its current hype-cycle with some genuine gains and progress. This time it is different. The fact that serious investment in AI is being made not just by corporations but by governments (including the UK) could be taken as an indicator that we are looking beyond the hype. Data volumes, compute power, and credible business models are all present simultaneously in this current AI/Machine Learning hype-cycle, in ways that they weren’t in the 1980s neural network boom-and-bust and other AI Winters. Machine Learning and Data Science is becoming genuinely commoditized. Consequently, the goal China has set itself is about building capacity, i.e. about the transfer of knowledge from a smaller innovation ecosystem (such as the academic community and a handful of large corporate labs) to produce a larger but highly-skilled bulk of practitioners. A capacity building exercise such as this should be a known quantity and so investments will scale – i.e. you will see proportional returns on those investments. The Nature news article does comment that China may face some challenges in strengthening the initial research base in AI, but this may be helped by the presence of large corporate players such as Microsoft and Google, who have established AI research labs within the country.
What sectors will be influenced most?
One prominent area for applications of AI and Machine Learning is commerce, and China provides a large potential market place. However, access to that market can be difficult for Western companies and so Chinese data science solution providers may face limited external competition on their home soil. Equally, Chinese firms wishing to compete in Western markets, using expertise of the AI-commerce interface gained from their home market, may face tough challenges from the mature and experienced incumbents present in those Western markets. Secondly, it may depend precisely on which organizations in China develop the beneficial experience in the sector. The large US corporates (Microsoft, Google) that have a presence in China are already main players in AI and commerce in the West, and so may not see extra dividends beyond the obvious ones of access to the Chinese market and access to emerging Chinese talent. Overall, it feels that whilst China’s investment in this sector will undoubtedly be a success, and Chinese commerce firms will be a success, China’s AI investment may not significantly change the direction the global commerce sector would have taken anyway with regard to its use and adoption of AI.
Perhaps more intriguing will be newer, younger sectors in which China has already made significant investment. Obvious examples, such as genomics, spring to mind, given the scale of activity by organizations such as BGI (including the AI-based genomic initiative of the BGI founder Jun Wang). Similarly, robotics is another field highlighted within the Nature articles.
What are China’s competitors investing in this area?
I will restrict my comments to the UK, which, being my home country, I am more familiar with. Like China, the UK has picked out AI, Robotics, and a Data Driven Economy as areas that will help enable a productive economy. Specifically, the UK Industrial Strategy announced last year identifies AI for one of its first ‘Sector Deals’ and also as one of four Grand Challenges. The benefits of AI is even called out in other Sector Deals, for example in the Sector Deal for the Life Sciences. This is on top of existing UK investment in Data Science, such as the Alan Turing Institute (ATI) and last year’s announcement by the ATI that it is adding four additional universities as partners. In addition we have capacity-building calls from research councils, such as the EPSRC call for proposals for Centres for Doctoral Training (CDTs). From my quick reading, 4 of the 30 priority areas that the EPSRC has highlighted for CDTs make explicit reference to AI, Data Science, or Autonomous Systems. The number of priority areas that will have some implicit dependence on AI or Data Science will be greater. Overall the scale of the UK investment is, naturally, unlikely to match that of China – the original Nature report on the Chinese plans says that no mention of level of funding is made. However, the likely scale of the Chinese governmental investment in AI will ultimately give that country an edge, or at least a higher probability of success. Does that mean the UK needs to re-think and up its investment?
Notes:
- An English-language government summary of the plan, published on the 20th July 2017, can be found here.
- A more detailed outline of the plan’s goals and policy is given in a Medium blog article by Jia He.
- An English-language copy of the plan can be found on the website of the non-profit organization the Foundation for Law and International Affairs (FLIA).

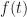 , evaluate the
, evaluate the  derivative of the composite function
derivative of the composite function 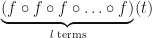 . That is, we define
. That is, we define  to be the function obtained by iterating the base function
to be the function obtained by iterating the base function 
 times. One approach is to make recursive use of the
times. One approach is to make recursive use of the  Eq.(1)
Eq.(1) are available within the
are available within the  symbolic algebra Python package, makes this initially an attractive route to evaluating the required derivatives. In particular, I am interested in evaluating the derivatives at
symbolic algebra Python package, makes this initially an attractive route to evaluating the required derivatives. In particular, I am interested in evaluating the derivatives at 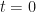 and I am focusing on odd functions of
and I am focusing on odd functions of  , for which
, for which 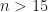 .
. Eq.(2)
Eq.(2)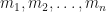 that satisfy
that satisfy  . That is, the sum is taken over all partitions of n. Fairly obviously the Faa di Bruno formula is just a re-arrangement of the above equation, made by collecting terms involving
. That is, the sum is taken over all partitions of n. Fairly obviously the Faa di Bruno formula is just a re-arrangement of the above equation, made by collecting terms involving 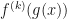 together, and as such that rearrangement gives the fundamental definition of the partial Bell polynomial.
together, and as such that rearrangement gives the fundamental definition of the partial Bell polynomial. using Eq.(2). First we generate and store the partitions,
using Eq.(2). First we generate and store the partitions, . A plot of the base function is shown below in Figure 1.
. A plot of the base function is shown below in Figure 1.

 Eq.(3)
Eq.(3)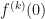 , of the base function is easy. The screenshot below shows a comparison of
, of the base function is easy. The screenshot below shows a comparison of  for
for  . As you can see we obtain identical output whether we use sympy’s Bell polynomials or sympy’s partition iterator.
. As you can see we obtain identical output whether we use sympy’s Bell polynomials or sympy’s partition iterator.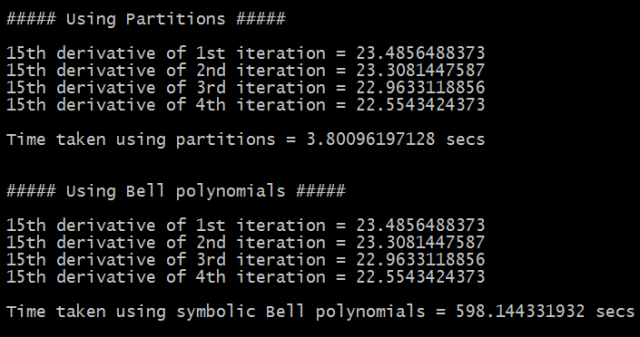
 , e.g.
, e.g. 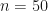 , can be tractable using the sympy package in python.
, can be tractable using the sympy package in python. derivative,
derivative, 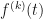 , of the base function at any point t and will return the derivatives,
, of the base function at any point t and will return the derivatives,  of the iterated function.
of the iterated function.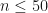 ), I need to work on the log scale, or whether direct evaluation of the summand will be sufficiently accurate and not result in overflow error.
), I need to work on the log scale, or whether direct evaluation of the summand will be sufficiently accurate and not result in overflow error.
 . After using the SciPy
. After using the SciPy  function I was scratching my head as to why I was seeing a discrepancy between my numerical calculations for the eigenvalues and my theoretical calculation. Then I came across this post
function I was scratching my head as to why I was seeing a discrepancy between my numerical calculations for the eigenvalues and my theoretical calculation. Then I came across this post 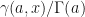 .
.